Pitfalls of linear sample reduction: Part 1
23 Jul 2019Two years ago I worked with Epic to try to improve the Unreal Engine animation compression codecs. While I managed to significantly improve the compression performance, despite my best intentions, a lot of research, and hard work, some of the ideas I tried failed to improve the decompression speed and memory footprint. In the end their numbers just didn’t add up when working at the scale Fortnite operates at.
I am now refactoring Unreal’s codec API to natively support animation compression plugins. As part of that effort, I am removing the experimental ideas I had added and I thought they deserved their own blog posts. There are many academic papers and posts about things that worked but very few about those that didn’t.
The UE4 codecs rely heavily on linear sample reduction: samples in a time series that can be linearly interpolated from their neighbors are removed to achieve compression. This technique is very common but it introduces a number of nuances that are often overlooked. We will look at some of these in this multi-part series:
- Splitting animation sequences into independent segments doesn’t work too well
- Sorting the samples in a CPU cache friendly memory layout has far reaching implications
- The added memory overhead when samples are removed is fairly large
- Empirical data shows that in practice not many samples are removed
TL;DR: As codecs grow in complexity, they can sometimes have unintended side-effects and ultimately be outperformed by simpler codecs.
What we are working with?
Animation data consists of a series of values at various points in time (a time series). These drive the rotation, translation, and scale of various bones in a character’s skeleton or in some object (prop). Both Unreal Engine and the Animation Compression Library work with a fixed number of samples (frames) per second. Storing animation curves where the samples can be placed at arbitrary points in time isn’t as common in video games. The series of rotation, translation, and scale are called tracks and all have the same length. Together they combine to form an animation clip that describes how multiple bone transforms evolve over time.
Compression is commonly achieved by:
- Removing samples that can be reconstructed by interpolating between the remaining neighbors
- Storing each sample using a reduced number of bits
Unreal Engine uses linear interpolation to reconstruct the samples it removes and it stores each track using 32, 48, or 96 bits per sample.
ACL retains every sample and stores each track using 9, 12, 16, … 96 bits per sample (19 possible bit rates).
Slice it up!
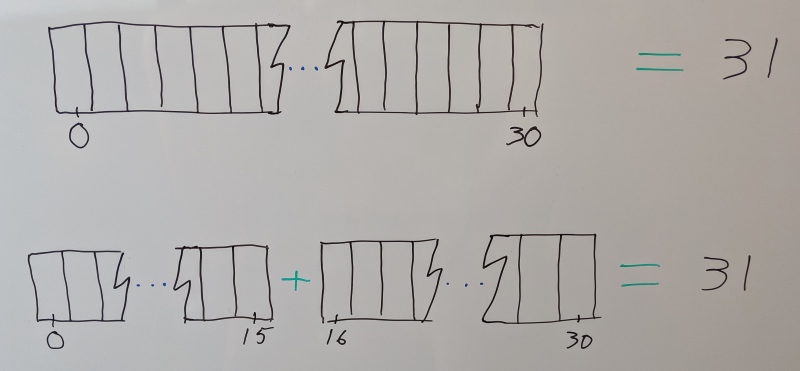
Segmenting a clip is the act of splitting it into a number of independent and contiguous segments. For example, we can split an animation sequence that has tracks with 31 samples each (1 second at 30 samples per second) into two segments with 16 and 15 samples per track.
Segmenting has a number of advantages:
- Values within a segment have a reduced range of motion which allows fewer bits to be used to represent them, achieving compression.
- When samples are removed we have to search for their neighbors to reconstruct their value. Segmenting allows us to narrow down the search faster, reducing the cost of seeking.
- Because all the data needed to sample a time
Tis within a contiguous segment, we can easily stream it from a slower medium or prefetch it. - If segments are small enough, they fit entirely within the processor L1 or L2 cache which leads to faster compression.
- Independent segments can trivially be compressed in parallel.
Around that time in the summer of 2017, I introduced segmenting into ACL and saw massive gains: the memory footprint reduced by roughly 36%.
ACL uses 16 samples per segment on average and having access to the animations from Paragon I looked at how many segments it had: 6558 clips turned into 49214 segments.
What a great idea to try with the UE4 codecs as well!
Segmenting in Unreal
Unfortunately, the Unreal Engine codecs were not designed with this concept in mind.
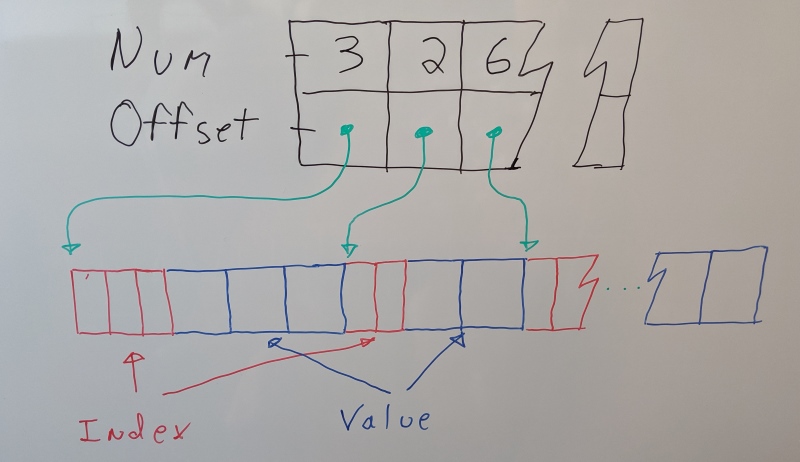
In order to keep decompression fast, each track stores an offset into the compressed byte stream where its data starts as well as the number of samples retained. This allows great performance if all you need is a single bone or when bones are decompressed in an order different from the one they were compressed in (this is quite common in UE4 for various reasons).
Unfortunately, this overhead must be repeated in every segment. To avoid the compressed clip’s size increasing too much, I settled on a segment size of 64 samples. But these larger segments came with some drawbacks:
- They are less likely to fit in the CPU L1 cache when compressing
- There are fewer opportunities for parallelism when compressing
- They don’t narrow the sample search as much when decompressing
Most of the Paragon clips are short. Roughly 60% of them need only a single segment. Only 19% had more than two segments. This meant most clips consumed the same amount of memory while being slightly slower to decompress. Only long cinematics like the Matinee fight scene showed significant gains on their memory footprint, compression performance, and decompression performance. In my experience working on multiple games, short clips are by far the most common and Paragon isn’t an outlier.
Overall, segmenting worked but it was very underwhelming within the UE4 codecs. It did not deliver what I had hoped it would and what I had seen with ACL.
In an effort to fix the decompression performance regression, a context object was introduced, adding even more complexity. A context object persists from frame to frame for each clip being played back. It allows data to be reused from a previous decompression call to speed up the next call. It is also necessary in order to support sorting the samples which I tried next and will be covered in my next post.