12 May 2018
Today marks the v0.8 release of the Animation Compression Library. It contains lots of goodies but by far the most significant point is the fact that it has now reached feature parity with Unreal 4. For the first time Unreal 4 games should be able to run exclusively with ACL. The focus for the next 2 months will be to validate this with my custom UE 4.15 integration and implement whatever might be missing as well as to create a proper and free plugin to bring ACL to the marketplace.
While I have already published some decompression performance numbers earlier this week, once a proper integration has been made, new numbers will be published to showcase how ACL performs against Unreal 4 within the game engine itself. The existing numbers for the Carnegie-Mellon University database, Paragon, and the Matinee fight scene already clearly show ACL to be ahead in terms of compression time, compression ratio, and accuracy. However, while it remains to be seen if it will also be ahead with its decompression performance, I fully expect that it will.
11 May 2018
At long last I finally got around to measuring the decompression performance of ACL. This blog post will detail the baseline performance from which we will measure future progress. As I have previously mentioned, no effort has been made so far to optimize the decompression and I hope to remedy that following the v1.0 release scheduled around June 2018.
In order to establish a reliable data set to measure against, I use the same 42 clips used for regression testing plus 5 more from the Matinee fight scene. To keep things interesting, I measure performance on everything I have on hand:
The first two use both x86 and x64 while the later two use armv7-a and arm64 respectively. Furthermore, on the desktop I also compare VS 2015, VS 2017, GCC 7, and Clang 5. The more data, the merrier!
Decompression is measured both with a warm CPU cache to remove the memory fetches as much as possible from the equation as well as with a cold CPU cache to simulate a more realistic game engine playback scenario.
Three forms of playback are measured: forward, backward, and random.
Each clip is sampled 3 times at every key frame based on the clip sample rate and the smallest value is retained for that key.
Finally, two ways to decompress are profiled: decompressing a whole pose in one go (decompress_pose), and decompressing a whole pose bone by bone (decompress_bone).
The profiling harness is not perfect but I hope the extensive data pulled from it will be sufficient for our purposes.
Playback direction
In a real game, the overwhelming majority of clips play forward in time. Some clips play backwards (e.g. opening and closing a chest might use the same animation played in reverse) and a few others play randomly (e.g. driven by a thumb stick).
Not all algorithms will exhibit the same performance regardless of playback direction. In particular, forms of delta encoding as well as any caching of the last played position will severely degrade when the playback isn’t the one optimized for (as is often the case with key reduction techniques due to the data being sorted by time).
ACL currently uses the uniformly sampled algorithm which offers consistent performance regardless of the playback direction. To validate this claim, I hand picked 3 clips that are fairly long: 104_30 (44 bones, 11 seconds) from CMU, and Trooper_1 (71 bones, 66 seconds) and Trooper_Main (541 bones, 66 seconds) from the Matinee fight scene. To visualize the performance, I used a box and whiskers chart which shows concisely the min/max as well as the quartiles. Forward playback is shown in Red, backward in Green, and random in Blue.
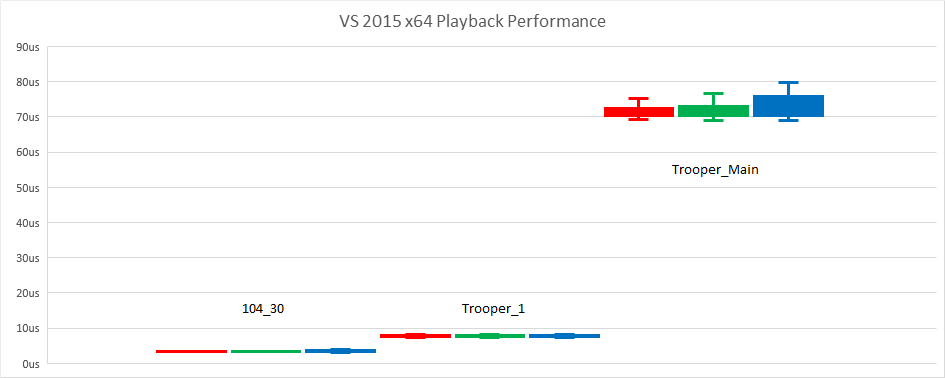
As we can see, the performance is identical for all intents and purposes regardless of the playback direction on my desktop with VS 2015 x64. Let’s see if this claim holds true on my iPad as well.
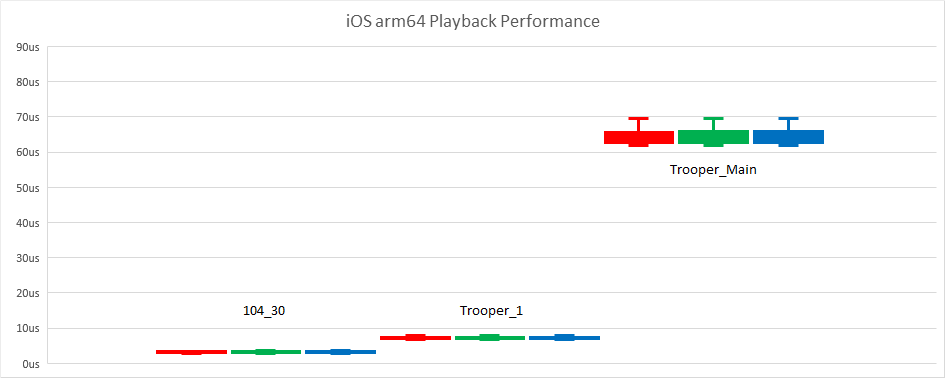
Here again we see that the performance is consistent. One thing that shows up on this chart is that, surprisingly, the iPad performance is often better than my desktop! That is INSANE and I nearly fell off my chair when I first saw this. Not only is the CPU clocked at a lower frequency but the desktop code makes use of SSE and AVX where it can for all basic vector arithmetic while there is currently no corresponding NEON SIMD support. I double and triple checked the numbers and the code. Suspecting that the compiler might be playing a big part in this, I undertook to dump all the compiler stats on desktop; something I did not originally intend to do. Read on!
The CPU cache
Because animation clips are typically sampled once per rendered image, the CPU cache will generally always be cold during decompression. Fortunately for us, modern CPUs offer hardware prefetching which greatly helps when reads are linear. The uniformly sampled algorithm ACL uses is uniquely optimized for this with ALL reads being linear and split into 4 streams: constant track values, clip range data, segment range data, and the animated segment data.
Notes: ACL does not currently have any software prefetching and the constant track and clip range data will later be merged into a single stream since a track is one of three types: default (in which case there is neither constant nor range data), constant with no range data, or animated with range data and thus not constant.
For this reason, a cold cache is what will most interest us. That being said, I also measured with a warm CPU cache. This will allow us to see how much time is spent waiting on memory versus executing instructions. It will also allow us to compare the various platforms in terms of CPU and memory speed.
In the following graphs, the x86 performance was omitted because for every compiler it is slower than x64 (ranging from 25% slower up to 200%) except for my OS X laptop where the performance was nearly identical. I also omitted the VS 2017 performance because it was identical to VS 2015. Forward playback is used along with decompress_pose. The median decompression time is shown.
Two new clips were added to the graphs to get a better picture.
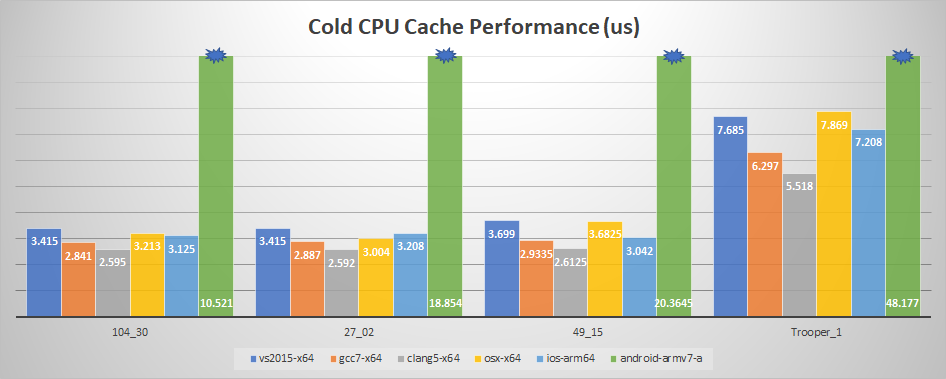
Again, we can see that the iPad outperforms almost everything with a cold cache except on the desktop with GCC 7 and Clang 5. It is clear that Clang does an outstanding job and plays an integral part in the surprising iPad performance. Another point worth noting is that its memory is faster than what I have in my desktop. My iPad has memory clocked at 1600 MHz (25 GB/s) while my desktop has its memory clocked at 1067 MHz (16.6 GB/s).
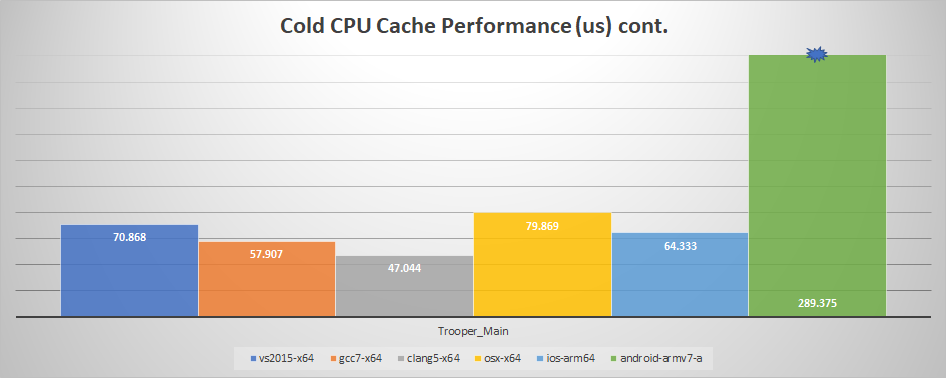
And now with a warm cache:
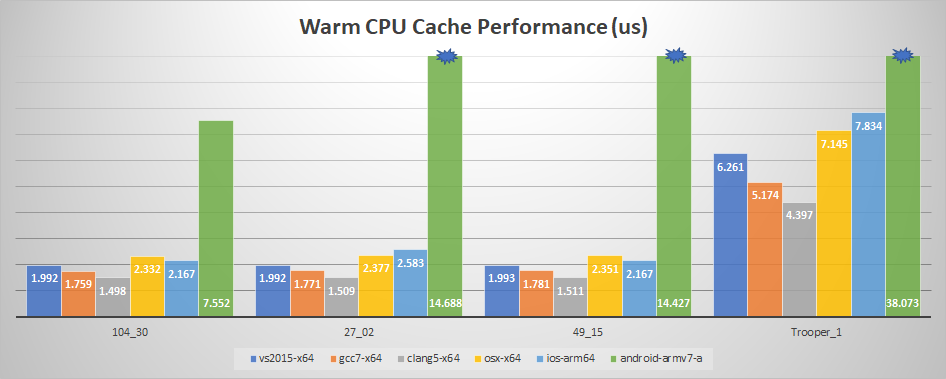
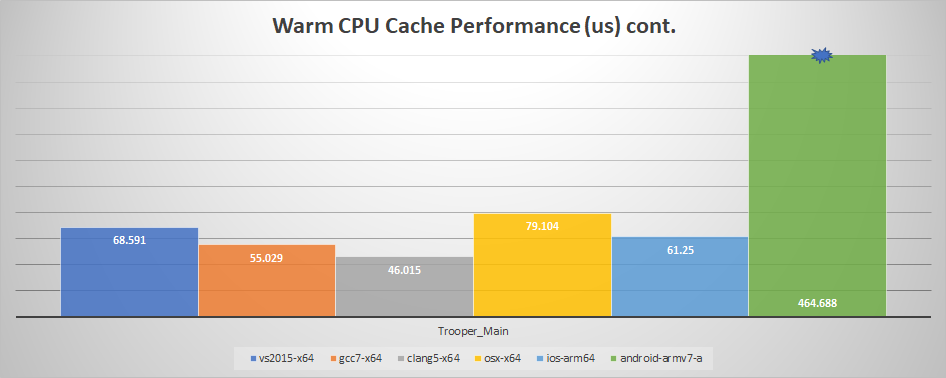
We can see that the iPad now loses out to VS 2015 with one exception: Trooper_Main. Why is that? That particular clip should easily fit within the CPU cache: only about 40KB is touched when sampling (or about 650 cache lines). Further research led to another interesting fact: the iPad A10X processor has a 64KB L1 data cache per core (and 8 MB L2 shared) while my i7-6850K has a 32KB L1 data cache and a 256KB L2 (with 15MB L3 shared). The clip thus fits entirely within the L1 on the iPad but needs to be fetched from the L2 on desktop.
Another takeaway from these graphs is that GCC 7 beats VS 2015 and Clang 5 beats both hands down on my desktop.
Finally, my Nexus 5X is really slow. On all the graphs, it exceeded any reasonable scale and I had to truncate it. I included it for the sake of completeness and to get a sense of how much slower it was.
Decompression method
ACL currently offers two ways to decompress: decompress_pose and decompress_bone. The former is more efficient if the whole pose is required but in practice it is very common to decompress specific bones individually or to decompress a pose bone by bone.
The following charts use the median decompression time with a cold CPU cache and forward playback.
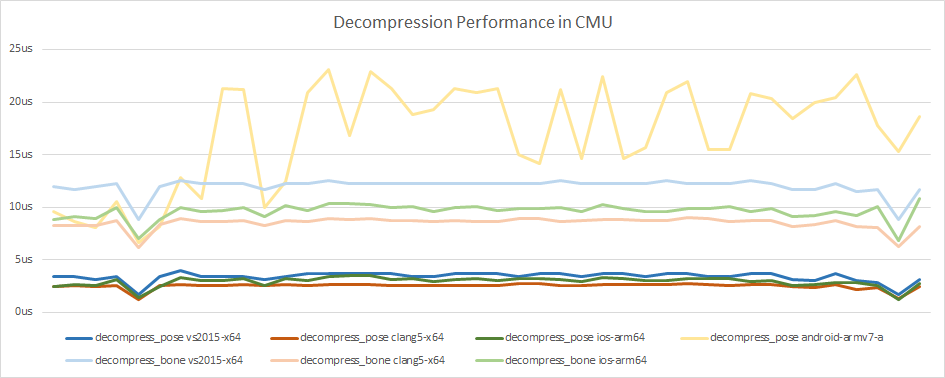
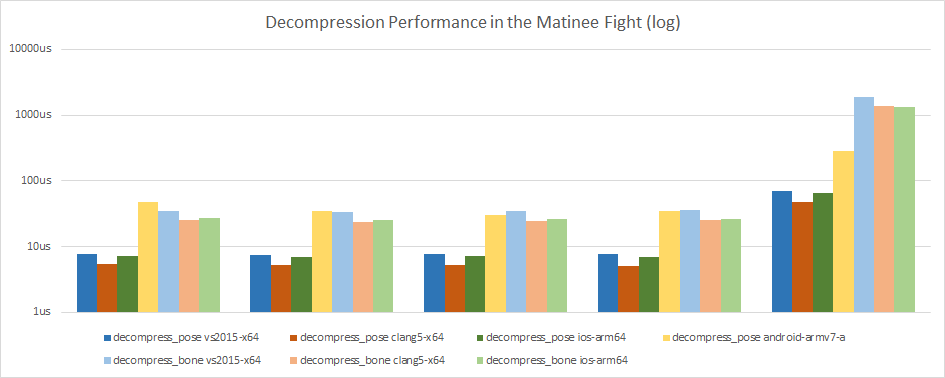
Once more, we see very clearly how outstanding and consistent the iPad performance is. The numbers for the Nexus 5X are very noisy in comparison in large part because of the slower memory and larger footprint of some clips (decompress_bone is not shown for Android because it was far too slow and prevented a clean view of everything else).
We can clearly see that decompressing each bone separately is much slower and this is entirely because at the time of writing, each bone not required needs to be skipped over instead of using a direct look up with an offset. This will be optimized soon and the performance should end up much closer.
Conclusion
Despite having no external reference frame to compare them against, I could confirm and validate my hunches as well as observe a few interesting things:
- My Nexus 5X is really slow …
- Both GCC 7 and Clang 5 generate much better code than VS 2017
decompress_bone is much slower than it needs to be- The playback direction has no impact on performance
By far the most surprising thing to me was the iPad performance. Even though what I measure is not representative of ordinary application code, the numbers clearly demonstrate that the single core decompression performance matches that of a modern desktop. It might even exceed the single core performance of an Xbox One or PlayStation 4! Wow!!
I do have some baseline Unreal 4 numbers on hand but this blog post is already getting long and the next ACL version aims to be integrated into a native Unreal 4 plugin which will allow for a superior comparison to be made. However, they do show that ACL will be very close and will likely exceed the UE 4.15 decompression performance; stay tuned!
08 May 2018
A common trick when compressing an animation clip is to store it relative to the bind pose. The conventional wisdom is that this allows to reduce the range of motion of many bones, increasing the accuracy and the likelihood that constant bones will turn into the identity, and thus allowing a lower memory footprint as a result. I have implemented this specific feature many times in the past and the results were consistent: a memory reduction of 3-5% was generally observed.
Now that the Animation Compression Library supports additive animation clips, I thought it would be a good idea to test this claim once more.
How it works
The concept is very simple to implement:
- Before compression happens, the bind pose is removed from the clip by subtracting it from every key.
- Then, the clip is compressed as usual.
- Finally, after we decompress a pose, we simply add back the bind pose.
The transformation is lossless aside from whatever loss happens as a result of floating point precision. It has two primary side effects.
The first is that bone translations end up having a much shorter range of motion. For example, a walking character might have the pelvic bone about 60cm up from the ground (and root bone). The range of motion will thus circle around this large value for the whole track. Removing the bind pose brings the track closer to zero since the bind pose value of that bone is likely very near 60cm. Smaller floating point values generally retain higher accuracy. The principle is identical to normalizing a track within its range.
The second impacts constant tracks. If the pelvic bone is not animated in a clip, it will retain some constant value. This value is often the bind pose itself. When this happens, removing the bind pose yields the identity rotation and translation. Since these values are trivial to reconstruct at runtime, instead of having to store the constant floating point values, we can store a simple bit set.
As a result, hand animated clips with the bind pose removed often find themselves with a lower memory footprint following compression.
Mathematically speaking, how the bind pose is added or removed can be done in a number of ways, much like additive animation clips. While additive animation clips heavily depend on the animation runtime, ACL now supports three variants:
- Relative space
- Additive space 0
- Additive space 1
The last two names are not very creative or descriptive… Suggestions welcome!
Relative space
In this space, the clip is reconstructed by multiplying the bind pose with a normal transform_mul operation. For example, this is the same operation used to convert from local space to object space. Performance wise, this is the slowest: to reconstruct our value we end up having to perform 3 quaternion multiplications and if negative scale is present in the clip, it is even slower (extra code not shown below, see here).
Transform transform_mul(const Transform& lhs, const Transform& rhs)
{
Quat rotation = quat_mul(lhs.rotation, rhs.rotation);
Vector4 translation = vector_add(quat_rotate(rhs.rotation, vector_mul(lhs.translation, rhs.scale)), rhs.translation);
return transform_set(rotation, translation, scale);
}
Additive space 0
This is the first of the two classic additive spaces. It simply multiplies the rotations, it adds the translations, and multiplies the scales. The animation runtime ozz-animation uses this format. Performance wise, this is the fastest implementation.
Transform transform_add0(const Transform& base, const Transform& additive)
{
Quat rotation = quat_mul(additive.rotation, base.rotation);
Vector4 translation = vector_add(additive.translation, base.translation);
Vector4 scale = vector_mul(additive.scale, base.scale);
return transform_set(rotation, translation, scale);
}
Additive space 1
This last additive space combines the base pose in the same way as the previous except for the scale component. This is the format used by Unreal 4. Performance wise, it is very close to the previous space but requires an extra instruction or two.
Transform transform_add1(const Transform& base, const Transform& additive)
{
Quat rotation = quat_mul(additive.rotation, base.rotation);
Vector4 translation = vector_add(additive.translation, base.translation);
Vector4 scale = vector_mul(vector_add(vector_set(1.0f), additive.scale), base.scale);
return transform_set(rotation, translation, scale);
}
It is worth noting that because these two additive spaces differ only by how they handle scale, if the animation clip has none, both methods will yield identical results.
Results
Measuring the impact is simple: I simply enabled all three modes one by one and compressed all of the Carnegie-Mellon University motion capture database as well as all of the Paragon data set. Decompression performance was not measured on its own but the compression time will serve as a hint as to how it would perform.
Everything has been measured with my desktop using Visual Studio 2015 with AVX support enabled with up to 4 clips being compressed in parallel. All measurements were performed with the upcoming ACL v0.8 release.

CMU has no scale and it is thus no surprise that the two additive formats perform the same. The memory footprint and the max error remain overall largely identical but as expected the compression time degrades. No gain is observed from this technique which further highlights how this data set differs from hand authored animations.

Paragon shows the results I was expecting. The memory footprint reduces by about 7.9% which is quite significant and the max error improves as well. Again, we can see both additive methods performing equally well. The relative space clearly loses out here and fails to show significant gains to compensate for the dramatically worse compression performance.
Conclusion
Overall it seems clear that any potential gains from this technique are heavily data dependent. A nearly 8% smaller memory footprint is nothing to spit at but in the grand scheme of things, it might no longer be worth it in 2018 when decompression performance is likely much more important, especially on mobile devices. It is not immediately clear to me if the reduction in memory footprint could save enough to translate into fewer cache lines being fetched but even so it seems unlikely that it would offset the extra cost of the math involved.
See also the related bind pose stripping optimization.
Back to table of contents
02 Apr 2018
Almost a year ago, I began working on ACL and it is now one step closer to being production ready with the new v0.7 release!
This new release is significant for several reasons but two stand out above all others:
- Exhaustive automated testing
- Full multi-platform support
Unlike previous releases, the performance remained unchanged since v0.6 but I went ahead and updated the stats and graphs regardless.
Testing, Testing, One, Two
This new release introduces extensive unit testing for all the core and math functions on top of which ACL is built. There is still lots of room for improvement here, contributions welcome! Continuous integration also executes the unit tests for every platform except iOS and Android where they must be executed manually for now.
More significant is the addition of exhaustive regression testing. A total of 42 clips from the Carnegie-Mellon University motion capture database are each compressed under a mix of 7 configurations. At the moment, these must be run manually for every platform but scripts are present to automate the whole process. The primary reason why it remains manual is that the data is too large for GitHub and I do not have a webserver to host it. The instructions can be found here.
It runs everywhere
ACL now officially supports 12 different compiler toolchains and all the major platforms: Windows, Linux, OS X, iOS, and Android. Both compression and decompression are supported and can easily be tested with the provided unit and regression tests.
But this is only the list of platforms I can reliably and easily test. In practice, since all the code is now pure C++11, if it compiles it should run just fine as-is. Although I cannot test them yet, I fully expect all major consoles to work out of the box: Nintendo Switch (ARM), PlayStation 4 (x64), and Xbox One (x64).
Paragon data
The data I obtained from Paragon under NDA last year may or may not differ from what has now been publicly released by Epic. As soon as I get the chance, I will update the published stats with the new public data. This also means that I will be able to include Paragon clips into the regression tests as well to increase our coverage.
Next steps
The next v0.8 release aims to achieve three goals (roadmap):
- Document as much as possible
- Add the remaining features to support real games
- Add the necessary decompression profiling infrastructure
Decompression performance is one of the most important metric for modern games on both mobile and consoles. Measuring it accurately and reliably in an environment that is as close to a real game as possible is challenging which is why it was left last. However, ACL was built from the ground up in order to decompress as fast as possible: all memory reads are contiguous and linear and writes can be too depending on the host game engine integration. I am quite confident it will end up competitive with the state of the art codecs within UE4 and there are many opportunities left to optimize that I have delayed until I can measure their individual impact properly.
This upcoming release is likely to be the last before the first production release which aims to be a drop-in replacement within UE4. If everything goes according to plan and no delays surface, at the current pace, I should be able to reach this milestone around June 2018.
10 Jan 2018
Hot off the press, ACL v0.6 has just been released and contains lots of great things!
This release focused primarily on extending the platform support as well as improving the accuracy. Proper Linux and OS X support was added as well as the x86 architecture. As always, the list of supported platforms is in the readme. This was made possible thanks to continuous build integration which has been added and contributed in part by Michał Janiszewski!
Another notable mention is that the backlog and roadmap have been migrated to GitHub Issues. This ensures complete transparency with where the project is going.
Compiler battle royal
Now that we have all of these compilers and platforms supported, I thought it would make sense to measure everything at least once on the full data set from Carnegie-Mellon University.
Another thing I wanted to measure is how much do we gain from hyper-threading and last but not least, I thought it would be interesting to include x86 as well as x64.
Here is my setup to measure:
- Windows 10 running on an Intel i7-6850K with 6 physical cores and 12 logical cores
- Ubuntu 16.04 running in VirtualBox with 6 cores assigned
- OS X running on an Intel i5-4288U with 2 physical cores and 4 logical cores
The acl_compressor.py script is used to compress multiple clips in parallel in independent processes. Each clip runs in its own process.
Every platform used a Release build with AVX enabled. The wall clock time is the cummulative time it took to run everything: compression, decompression to measure accuracy, reading the clip, writing the stats, etc. On the other hand, the total thread time measures the total sum of time the threads each spent on compression.
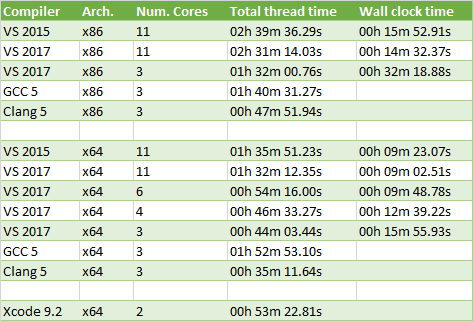
A number of things stand out:
- x86 is slower for VS 2015 (66.5% slower) , VS 2017 (64.0% slower with 11 cores, 108.8% slower with 3 cores), and Clang 5 (36.0% slower) but it seems to be faster for GCC 5 (10.9% faster)
- Hyper-threading barely helps at all: going from 6 cores to 11 with VS 2017 was only 7.8% faster but the total thread time increases by 69.9%
- Clang 5 with x64 wins hands down, it is 25.2% faster than VS 2017 and 220.8% faster than GCC 5
GCC 5 performs so bad here that I am wondering if the default CMake compiler flags for Release builds are sane or if I made a mistake somewhere. Clang 5 really blew me away: despite running in a VM it significantly outperforms all the other compilers with both x86 and x64.
As expected, hyper-threading does not help all that much. When clips are compressed, most of the data manipulated can fit within the L2 or L3 caches. With so little IO made, animation compression is primarily CPU bound. Overall this leaves very little opportunity for a neighbor thread to execute since they hardly ever stall on expensive operations.
Accuracy improvements
As I mentioned when the Paragon data set was announced, some exotic clips brought to the surface some unusual accuracy issues. These were all investigated and they generally fell into one or both of these categories:
- Very small and very large scale coupled with very large translation caused unacceptable accuracy loss when using affine matrices to calculate the error
- Very large translations in a long bone chain can lead to significant accuracy loss
In order to fix the first issue, how we handle the error metric was refactored to better allow a game engine to supply their own. This is documented here. Ultimately what is most important about the error metric is that it closely approximates how the error will look in the host game engine. Some game engines use affine matrices to convert the local space bone transform into object or world space while others use Vector-Quaternion-Vector (VQV). ACL now supports both ways to calculate the error and the default we will be using for all of our statistics is the later as it more closely matches what Unreal 4 does. This did not measurably impact the compression results but it did improve the accuracy of the more exotic clips and the overall compression time is faster.
However, the problem of large translations in long bone chains has not been addressed. I compared how the error looked in Unreal 4 and it does a much better job than ACL for the time being on those few clips. This is because they implement error compensation which is something that ACL has not implemented yet. In the meantime, ACL is perfectly safe for production use and if these rare clips with a visible error do pop up, less aggressive compression settings can be used. Only 3 clips within the Paragon data set suffer from this.
Ultimately a lot of the error introduced for both ACL and Unreal 4 comes from the rotation format we use internally: we drop the quaternion W component. This works well enough when its value is close to 1.0 as the square-root used to reconstruct it is accurate in that range but it fails spectacularly when the value is very small and close to 0.0. I already have plans to try two other rotation formats to help resolve this issue: dropping the largest quaternion component and using the quaternion logarithm instead.
Updated stats
While investigating the accuracy issues and comparing against Unreal 4 I noticed that a fix I previously made locally was partially incorrect and in rare cases could lead to bad things happening. This has been fixed and the statistics and graphs for UE 4.15 were updated for CMU and Paragon. The results are very close to what they were before.
The accuracy improvements from this release are a bit more visible on the Paragon data set.
Next steps
At this point, I can pretty confidently say that ACL is ready for production use but many things are still missing for the library to be of production quality. While the performance and accuracy are good enough, iOS support is still missing, support for additive animations is missing, as well as lots of unit testing, documentation, and clean up.
The next release will focus on:
- Cleaning up
- Adding lots of unit tests
- iOS support
- Better Android support
- Many other things