As I mentioned in my previous post, ACL still suffers from some less then ideal accuracy in some exotic situations. Since the next release will have a strong focus on fixing this, I wanted to investigate using float64 and fixed point arithmetic. It is general knowledge that float32 arithmetic incurs rounding and can lead to severe accuracy loss in some cases. The question I hoped to answer was whether or not this had a significant impact on ACL. Originally ACL performed the compression entirely with float64 arithmetic but this was removed because it caused more issues than it was worth but I did not publish numbers to back this claim up. Now we revisit it once and for all.
To this end, the first research branch was created. Research branches will play an important role in ACL. Their aim is to explore small and large ideas that we might not want to support in their entirety in the main branches while keeping them close. Unless otherwise specified, research branches will not be actively maintained. Once their purpose is complete, they will live on to document what worked and didn’t work and serve as a starting point for anyone hoping to investigate them further.
float64 vs float32 arithmetic
In order to fully test float64 arithmetic, I templated a few things to abstract the arithmetic used between float32 and float64. This allowed easy conversion and support of both with nearly the same code path. The results proved somewhat underwhelming:
As it turns out, the small accuracy loss from float32 arithmetic has a barely measurable impact on the memory footprint for CMU and a 0.6% reduction for Paragon. However, the compression (and decompression) time is much faster.
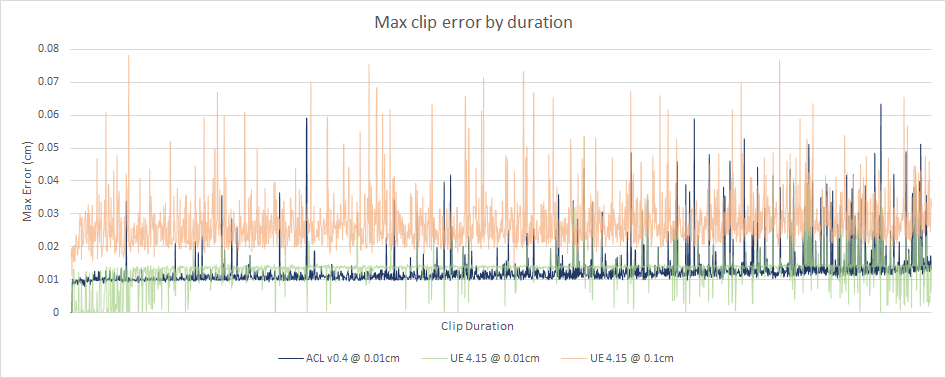
With float64, the max error for CMU and Paragon is slightly improved for the majority of the clips but not by a significant margin and 4 exotic Paragon clips end up with a worse error.
Consequently, it is my opinion that float32 is the superior choice between the two. The small increase in accuracy and reduction in memory footprint is not significant enough to outweigh the degradation of the performance. Even though the float64 code path isn’t as optimized, it will remain slower due to the individual instructions being slower and the increased number of registers needed. It’s possible the performance might be improved considerably with AVX and so this is something we’ll keep in mind going forward.
Fixed point arithmetic
Another popular alternative to floating point arithmetic is fixed point arithmetic. Depending on the situation it can yield higher accuracy and depending on the hardware it can also be faster. Prior to this, I had never worked with fixed point arithmetic. There was a bit of a learning curve but it proved intuitive soon enough.
I will not explain in great detail how it works but intuitively, it is the same as floating point arithmetic minus the exponent part. For our purposes, during the decompression (and part of the compression), most of the values we work with are normalized and unsigned. This means that the range is known ahead of time and fixed which makes it a good candidate for fixed point arithmetic.
Sadly, it differs so much from floating point arithmetic that I could not as easily support it in parallel with the other two. Instead, I created an arithmetic_playground and tried a whole bunch of things within.
I focused on reproducing the decompression logic as close as possible. The original high level logic to decompress a single value is simple enough to include here:
Not quite 1.0
The first obstacle to using fixed point arithmetic is the fact that our quantized values do not map 1:1. Many engines dequantize with code that looks like this (including Unreal 4 and ACL):
This is great in that it allows us to exactly represent both 0.0 and 1.0, we can support the full range we care about: [0.0 .. 1.0]. A case could be made to use a multiplication instead but it doesn’t matter all that much for the present discussion. With fixed point arithmetic we want to use all of our bits to represent the fractional part between those two values. This means the range of values we support is: [0.0 … 1.0). This is because both 0.0 and 1.0 have the same fractional value of 0 and as such we cannot tell them apart without an extra bit to represent the integral part.
In order to properly support our full range of values, we must remap it with a multiplication.
Fast coercion to float32
The next hurdle I faced was how to convert the fixed point number into a float32 value efficiently. I independently found a simple, fast, and elegant way and of course it turned out to be very popular for those very reasons.
For all of our possible values, we know their bit width and a shift can trivially be calculated to align it with the float32 mantissa. All that remains is or-ing the exponent and the sign. In our case, our values are between [0.0 … 1.0[ and thus by using a hex value of 0x3F800000 for exponent_sign, we end up with a float32 in the range of [1.0 … 2.0[. A final subtraction yields us the range we want.
Using this trick with the float32 implementation gives us the following code:
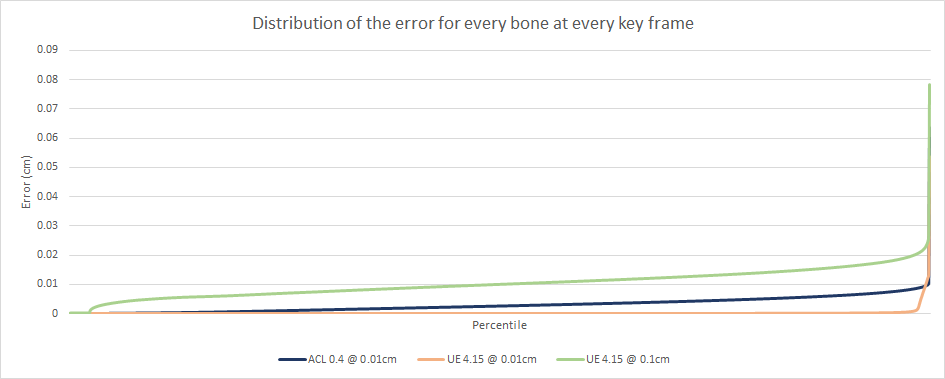
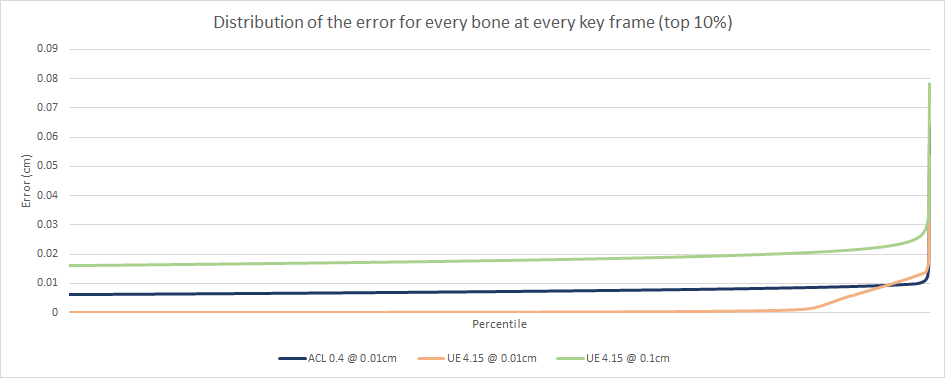
It does lose out a tiny bit of accuracy but it is barely measurable. In order to be sure, I tried exhaustively all possible sample and segment range values up to a bit rate of 16 bits per component. The up side is obvious, it is 14.9% faster!
32 bit vs 64 bit variants
Many variants were implemented: some performed the segment range expansion with fixed point arithmetic and the clip range expansion with float32 arithmetic and others do everything with fixed point. A mix of 32 bit and 64 bit arithmetic was also tried to compare the accuracy and performance tradeoff.
Generally, the 32 bit variants had a much higher loss of accuracy by 1-2 orders of magnitude. It isn’t clear how much this would impact the overall memory footprint on CMU and Paragon. The 64 bit variants had comparable accuracy to float32 arithmetic but ended up using more registers and more instructions. This often degraded the performance to the point of making them entirely uncompetitive in this synthetic test. Only a single variant came close to the original float32 performance but it could never beat the fast coercion derivative.
The fastest 32 bit variant is as follow:
Despite being 3 instructions shorter and using faster instructions, it was 14.4% slower than the fast coercion float32 variant. This is likely a result of pipelining not working out as well. It is entirely possible that in the real decompression code things could end up pipelining better making this a faster variant. Other processors such as those used in consoles and mobile devices also might perform differently and proper measuring will be required to get a definitive answer.
The general consensus seems to be that fixed point arithmetic can yield higher accuracy and performance but it is highly dependent on the data, the algorithm, and the processor it runs on. I can corroborate this and conclude that it might not help out all that much for animation compression and decompression.
Next steps
All of this work was performed in a branch that will NOT be merged into develop. However, some changes will be cherry picked by hand. In the short term, the conclusions reached here will not be integrated just yet into the main branches. The primary reason for this is that while I have extensive scripts and tools to track the accuracy, memory footprint, and compression performance; I do not have robust tooling in place to track decompression performance on the various platforms that are important to us.
Once we are ready, the fast coercion variant will land first as it appears to be an obvious drop-in replacement and some fixed point variants will also be tried on various platforms.
The accuracy issues will have to be fixed some other way and I already have some good ideas how: idea 1, idea 2, idea 3, idea 4, idea 5.
While working for Epic to improve Unreal 4’s own animation compression and decompression, I asked for permission to use the Paragon animations for research purposes and they generously agreed. Today I have the pleasure to report the findings from that new data set!
This is significant for two reasons:
It allows for extensive stress testing with new data
Paragon is a real game with high animation quality
The data set contains 2534 clips. Each clip contains an animated character with 44 bones. The version of the data that I found comes from the Unity store where it is distributed in FBX form but sampled at 24 FPS. The total duration of the database is 09h 49m 37.58s. It does not contain any 3D scale and its raw size is 1429.38 MB. It exclusively contains motion capture animation data. It is publicly available and well known within the animation compression research community.
While the database is valuable, it is not entirely representative of all the animation assets that a AAA game might use for a few reasons:
Most AAA games today have well over 100 bones per character and sometimes as high as 500
The sample rate is lower than the 30 FPS typically used in games
Motion capture data is often very noisy
Games often animate things other than characters such as cloth, objects, destruction, etc.
Many games make use of 3D scale
For these reasons, this data set is wonderful for unit testing and establishing a baseline for comparison but it falls a bit short with what I would ideally like.
You can see how Unreal and ACL compare against it here.
Paragon
The Paragon data set contains 6558 clips for a total duration of 07h 00m 45.27s and a raw size of 4276.11 MB. As you can see, despite being shorter than CMU, it is about 3x larger in size.
The data set contains among other things:
Lots of characters with varying number of bones
Animated objects of various shape and form
Very short and very long clips
Clips with unusual sample rate (as low as 2 FPS!)
World space clips
Lots of 3D scale
Lots of other exotic clips
This is great to stress test any compression algorithm and the results will be very representative of what could be expected in a AAA game.
To extract the animation clips, I used the Unreal 4 animation recompression commandlet and modified it to skip clips that ACL does not yet support (e.g. additive animations). I did my best to retain as many clips as possible. Every clip was saved in the ACL file format allowing a binary exact representation.
Sadly, I am not at liberty to share this data set as I am only allowed to use it under a non-disclosure agreement. All hope is not lost though, Epic has expressed interest in perhaps making a small subset of the data publicly available for research purposes. Stay tuned!
Bugs!
The value of undertaking this quickly became obvious when an exotic clip from the data set highlighted a bug in the variable bit rate selection that ACL used. A fix was made and the results were breathtaking: CMU reduced in size by 19% (and Paragon reduced by 20%)! You can read about it here in my previous blog post.
Three clips stress tested the accuracy of ACL and ended up with an unacceptable error as a result. This will be made evident by the graphs and numbers below. I am hoping to fix a number of accuracy issues in the next ACL release now that I have new data to validate against.
The bugs I found were not exclusively within ACL: two were found and still present in the latest Unreal 4 version. Thankfully, I was able to get in touch with Epic and these should be fixed in a future release.
In order to make the comparison as fair as possible, I had to locally disable the down-sampling variants within the Unreal 4 automatic compression method. One of the two bugs caused these variants to sometime crash. While down-sampling isn’t often selected by the algorithm as the optimal choice for any given clip, disabling it means that compression is faster and possibly a bit larger as a result. Out of the 600 clips I managed to compress before finding the bug, only 3 ended up down-sampled. There are 9 down-sampled variants out of 27 in total (33%).
Bottom line
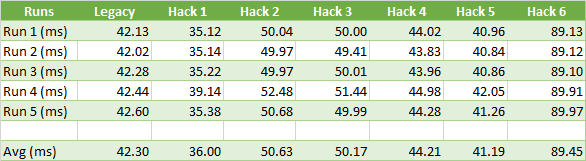
UE 4.15 took 19h 56m 50.37s single threaded to compress. It yielded a compressed size of 496.24 MB for a compression ratio of 8.62 : 1. The max error is 0.8619cm.
ACL 0.5 took 19h 04m 25.11s single threaded to compress (01h 53m 42.84s with 11 threads). It yielded a compressed size of 205.69 MB for a compression ratio of 20.79 : 1. The max error is 9.7920cm.
On the surface, the compression time remains faster with ACL even with a significant portion of the variants disabled in the Unreal automatic compression. However, the memory footprint is dramatically smaller, a whooping 58.6% smaller! As will be made apparent in the graphs below, once again the maximum error proves to be a poor metric of the true performance: 3 clips have an error above 0.8cm with ACL.
The results in images
All the results and many more images are also on GitHub here for Paragon just like they are for CMU here. I will only show a few selected images in this post for brevity.
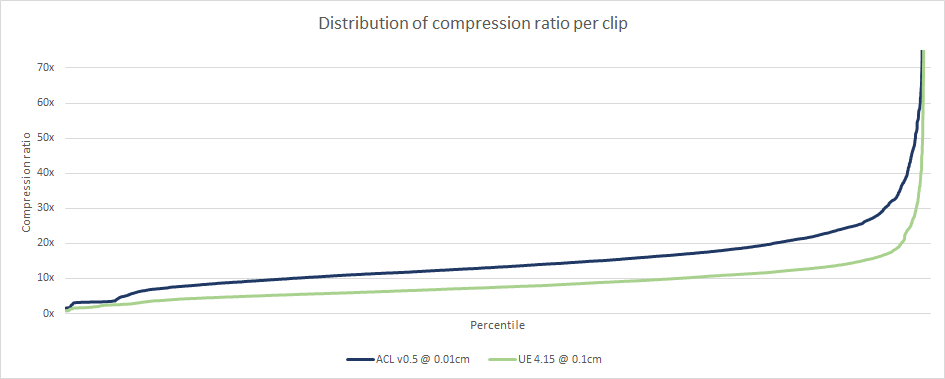
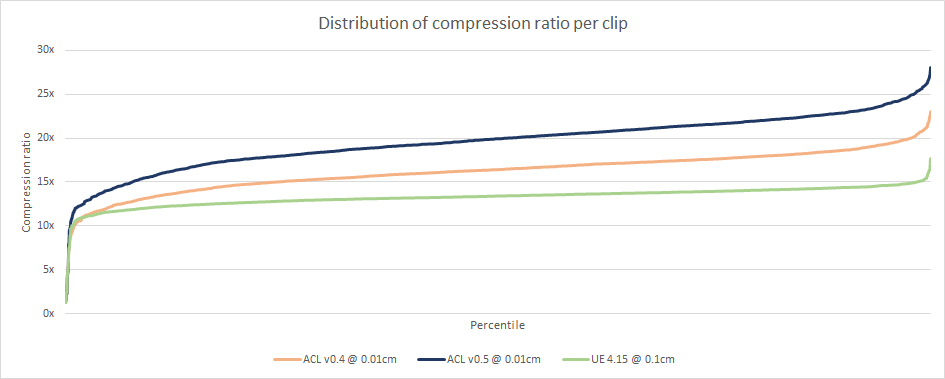
As expected, ACL outperforms Unreal by a significant margin. Some clips on the right are truncated with unusually high compression ratios as high as 900 : 1 for some exotic clips but those are likely very long with little to no animated data and aren’t too interesting or representative.
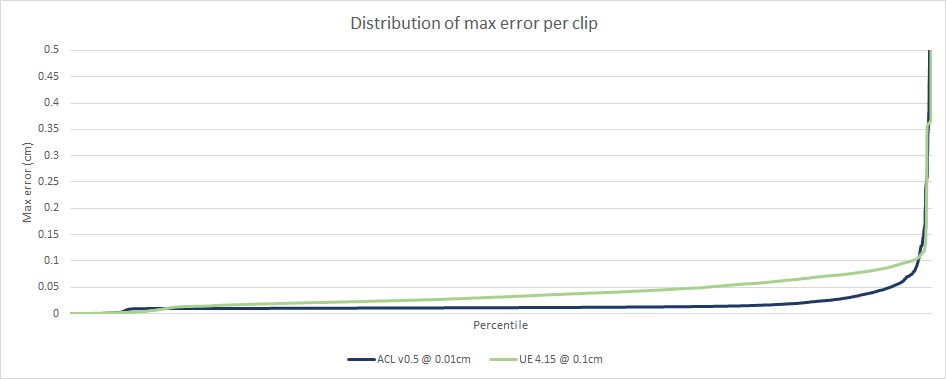
Here again ACL outperforms Unreal over the overwhelming majority of the data set. On the right there are a small number of clips that perform somewhat poorly with both compression methods: a total of 101 clips have an error above 0.1cm with ACL and 153 clips for Unreal.
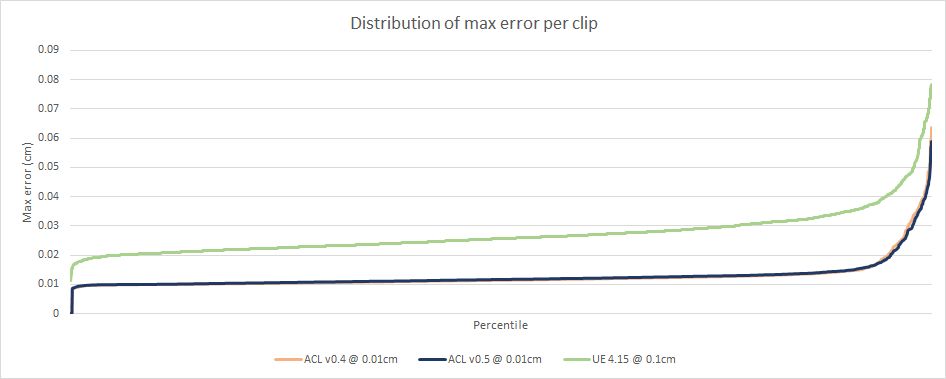
As I have previously mentioned, the max clip error is a poor measure of accuracy. Once again the full picture is much better and tells a different story.
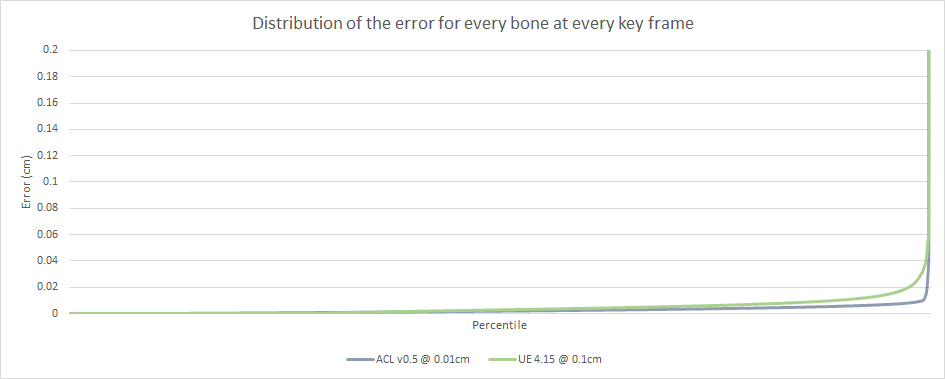
ACL continues to shine, crossing the 0.01cm threshold at the 99.23th percentile. Unreal crosses the same threshold at the 89th percentile.
Despite having a maximum error that is entirely unacceptable, it turns out that only 0.77% of the compressed samples (out of 112 million) exceed a sub-millimeter threshold. Aside from the 3 worst offending clips, everything else is cinematic and production quality. Not bad!
Conclusion
As is apparent now, ACL performs admirably in a myriad of scenarios and continues to improve month after month. Real world data now confirms it. Half the memory footprint of Unreal is not insignificant even for a PC or PS4 game: less data to load into memory means faster streaming, less data to transfer means faster game download and installation times, and it can correlate with faster decompression performance too. For many PS4 and XB1 games, 200 MB is perhaps small enough to load them all into memory up front and never stream them from disk afterwards.
As I continue to improve ACL, I will update the graphs and numbers with the latest significant releases. I also expect the improvements that I made to Unreal’s own animation compression over the last few months to be part of a future release and when that happens I will again update everything.
Special thanks to Raymond Barbiero for his very valuable feedback and to the continued support of many others!
Today marks the release of ACL v0.5. Once again, lots of great things were included in this release but three things stand out:
Full 3D scale support
Android support (tested within Unreal Engine 4.15)
A fix to the variable quantization optimization algorithm
The third point in particular needs explaining. Initially, I did not intend to make significant changes in this release to the way compression was done beyond the scale support and whatever fixes Android required.
However, while investigating accuracy issues within an exotic clip, I noticed a bug. Upon fixing it (and very unexpectedly), everything kicked into overdrive.
Performance results
On the Carnegie-Mellon University (CMU) data set, the memory footprint reduced by 18.4% with little to no change to the accuracy of the overwhelming majority of clips and a slight accuracy increase to some of them!
Sadly, the compression speed suffered a bit as a result and it is now about 1.5x slower than v0.4. In my opinion, this is an entirely acceptable trade-off!
Compared to UE 4.15, ACL now stands 37.8% smaller and 2.82x faster (single threaded) to compress on CMU. No small feat!
In light of these new numbers, all the charts have been updated and can be found here. Here are the most interesting:
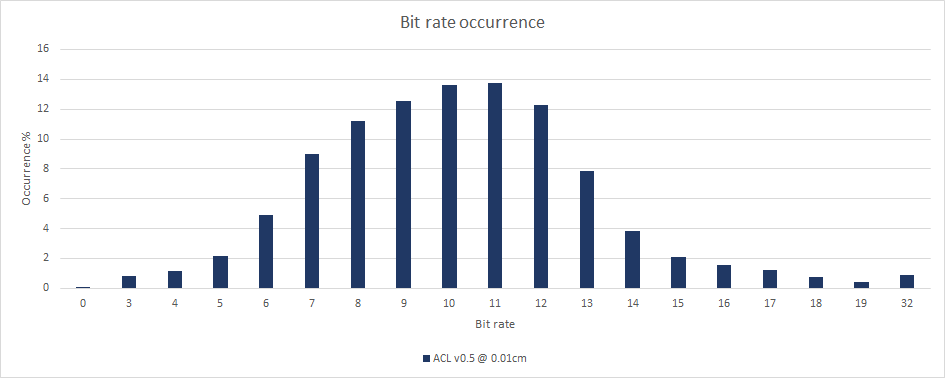
I also extracted two new charts: the distribution of clip durations within CMU and the distribution of which bit rates ended up selected by the algorithm. A bit rate of 6 means that 6 bits per component are used. Every track (rotation, translation, and scale) sample has 3 components (X, Y, Z) which means 18 bits per sample.
Next steps
The focus of the next few months will be more platform support (Linux, OS X, and iOS in that order) as well as improving the accuracy. A new data set I got my hands on showed edge cases that are not too uncommon from real video games where the accuracy is not good enough. Part of the accuracy loss comes from storing the segment range on 8 bits per component and the fact that we use 32 bit floats to perform the decompression arithmetic. As such, a new research branch will be created to investigate using 64 bit floats to perform the arithmetic and a fixed point represetation as well. A separate blog post will be written with the conclusion of this research.
As mentioned in my previous post, I started working on integrating ACL into Unreal 4.15 locally. Today I can finally confirm that not only does it work but it rocks!
Matinee fight scene
In order to stress test ACL in a real game engine with real content, I set out to test it on the Matinee fight scene that can be found on the Unreal 4 Marketplace.
ACL in action
This is a very complex sequence with fast movements and LOTS of data. The main character (the white trooper) has over 540 bones because the whole cloth motion is baked. The sequence lasts about 66 seconds. The secondary characters move in and out of view and overall spend the overwhelming majority of the sequence completely idle and off screen.
Here is a short extract of the sequence using ACL for every character. This marks the first visual test and confirmation that ACL works.
The data
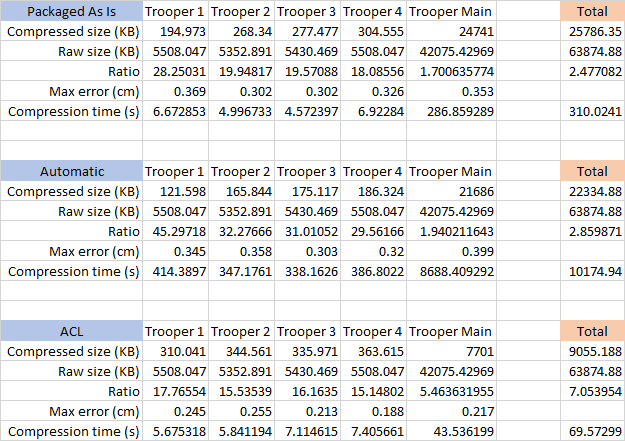
The video isn’t too interesting but once again the numbers tell a story of their own. Packaged As Is is the default settings used when you first open it up in the editor, as packaged on the marketplace. For ACL, the integration is somewhat dirty for now and uses the same settings as for the CMU database: the error is measured 3cm away from the bones, the error threshold is 0.1mm, and the segments are 16 frames long.
ACL completely surpassed my own expectations here. The whole sequence is 59.5% smaller! The main trooper is a whopping 64.5% smaller! That’s nearly 3x smaller! Compression time is also entirely reasonable sitting at just over 1 minute. While the packaged settings are decent here sitting at around 5 minutes, the automatic compression setting is not practical with almost 3 hours. The error shown is what Unreal 4 reports in the dialog box after compression, it thus uses the Unreal 4 error metric and here again we can see that ACL is superior.
However, ACL does not perform as good on the secondary characters and ends up significantly larger. This is because they are mostly idle. Idle bones compress extremely well with linear key reduction but because ACL uses short segments, it is forced to retain at least a single key per segment. With some sort of automatic segment partitioning the memory footprint could reduce quite a bit here or even by simply using larger segments.
What happens now?
The integration that I have made will not be public or published for quite some time. Until we reach version 1.0, I wouldn’t want to support actual games while I am still potentially making large changes to the library. Once ACL is production ready and robust, I will see with Epic how we can go about making ACL a first-class citizen in their engine. In the meantime, I will maintain it locally and use it to test and validate ACL on the other platforms supported by Unreal.
For the time being, all hope is not lost! For the past 2 months, I have been working with Epic on improving the stock Unreal 4 animation compression. Our primary focus has been to improve decompression speed and reduce the compression time without compromising the already excellent memory footprint and accuracy. If all goes well these changes should make it in the next release and once that happens, I will update the relevant charts and graphs published here as well as in the ACL documentation.
This marks the fourth release of ACL. It contains a lot of good stuff but most notable is the addition of segmenting support. I have not had the chance to play with the settings much yet but using segments of 16 key frames reduces the memory footprint by about 13% with variable quantization under uniform sampling. Adding range reduction on top of it (per segment), further reduces the memory footprint by another 10%. This is very significant!
Some optimizations also made it in to the compression time, reducing it by 4.3x with no compromise to quality.
You can see the latest numbers here as well as how they compare against the previous releases here. Note that the documentation contains more graphs than I will share here.
This also represents the first release where graphs have been generated allowing us an unprecedented view into how the ACL and Unreal algorithms perform. As such, I will detail what is note-worthy and thus this blog post will be a bit long. Grab a coffee and buckle up!
TL;DR:
ACL compresses better than Unreal for nearly every clip in the CMU database.
ACL is much smaller than Unreal (23.4%), is more accurate (2x+), and compresses much faster (4.68x).
ACL performs as expected and optimizes properly for the error threshold used, validating our assumptions.
A threshold of 0.1cm is good enough for production use in Unreal as the overwhelming majority (98.15%) of the samples have an error smaller than 0.02cm.
Why compare against Unreal?
As I have previously mentioned, Unreal 4 has a very solid error metric and good implementations of common animation compression techniques. It most definitely is well representative of the state of animation compression in game engines everywhere.
NOTE: In the images that follow, the results for an error threshold of UE4 @ 1.0cm were nearly identical to 0.1cm and were thus omitted for brevity
Performance results
ACL 0.4 compresses the CMU database down to 82.25mb in 50 minutes single-threaded and 5 minutes multi-threaded with a maximum error of 0.0635cm. Unreal 4.15 compresses it down to 107.94mb in 3 hours and 54 minutes single-threaded with a maximum error of 0.0850cm (1.0cm threshold used). Importantly, this is achieved with no compromise to decompression speed (although not yet measured, is estimated to be faster or just as fast with ACL).
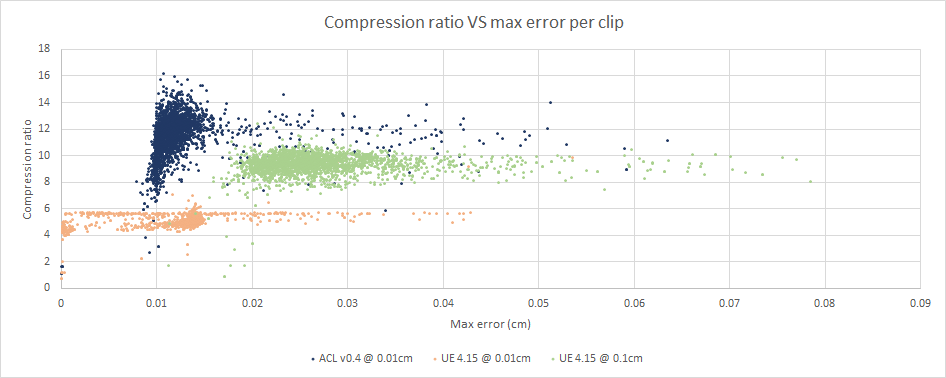
As can be seen on the above image, ACL performs quite well here. The error is very low and the compression quite high in comparison to Unreal.
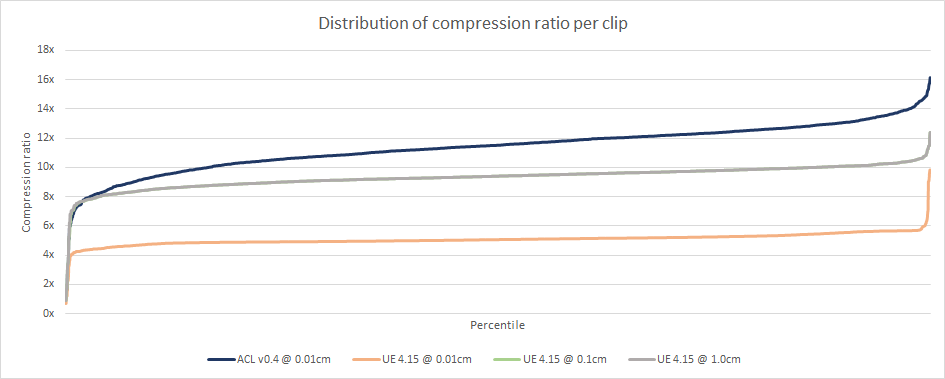
Here we see the full distribution of the compression ratio over the CMU database. UE4 @ 0.01cm fails to do better than dropping the quaternion W and storing everything as full precision most of the time which is why the compression ratio is so consistent. UE4 @ 0.1cm performs similarly in that key reduction fails very often on this database and as a result simple quantization is most often selected.
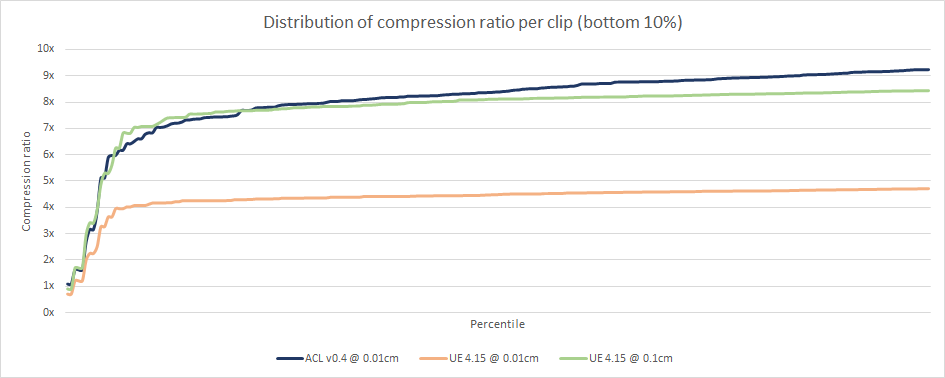
Here is a snapshot of the bottom 10% (10th percentile and lower). We can see some similarities in shape at the bottom and top 10%.
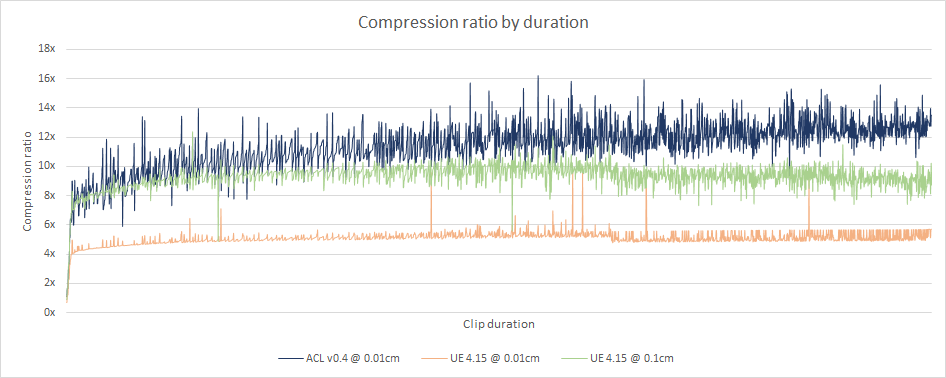
We can see on the above image that Unreal performs consistently regardless of the animation clip duration but ACL performs slightly better the longer the clip is. This is most likely a direct result of using range reduction twice: once per clip, and once per segment.
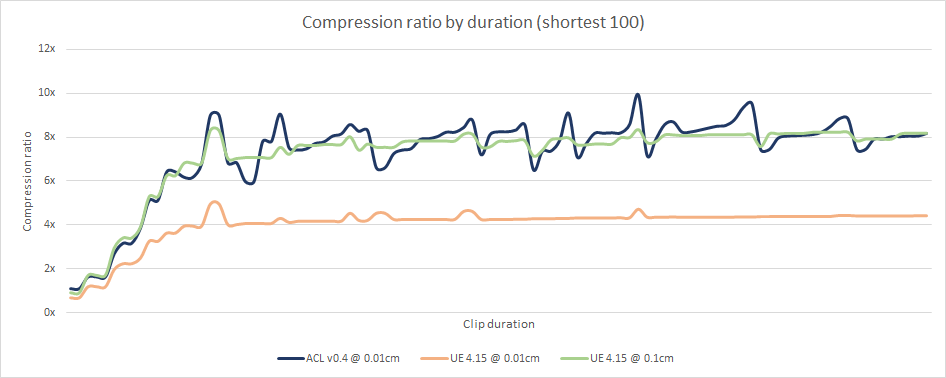
Both algorithms perform similarly for the shortest clips.
How accurate are we?
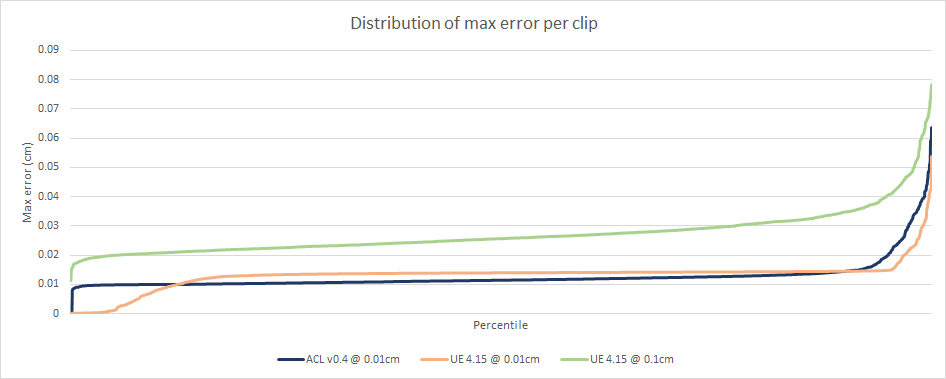
The above image gives a good view of how accurate the algorithms are. We can see ACL @ 0.01cm and UE4 @ 0.01cm quickly reach the error threshold and only about 10% of the clips exceed it. UE4 @ 0.1cm is less accurate but still pretty good overall.
The biggest source of error in both ACL and Unreal comes from the usage of the simple quaternion format consisting of dropping the W component to later reconstruct it at runtime. As it turns out, this is terribly inaccurate when that component is very small. Better formats exist and will be implemented later.
ACL performs worse on a larger number of clips likely as a result of range reduction sometimes causing a precision loss for some clips. At some point ACL should be able to detect this and turn it off if it isn’t needed.
There does not appear to be any correlation between the max error in a clip and its duration, as expected. One thing stands out though, the longer a clip is, the noisier the error appears to be. This is because the longer a clip is the more likely it is to contain a bad quaternion W that fails to reconstruct properly.
Over the years, I’ve read my fair share of animation compression papers and posts. And while they all measure the error differently the one thing they have in common is that they only talk about the worst error within a clip (or whole set of clips). As I have previously mentioned, how you measure the error is very important and must be done carefully but that is not all. Using the worst error within a given clip does not give a full picture. What about the other bones in the clip? What about the other key frames? Do I have a single bone on a single key frame that violates my threshold or do I have many?
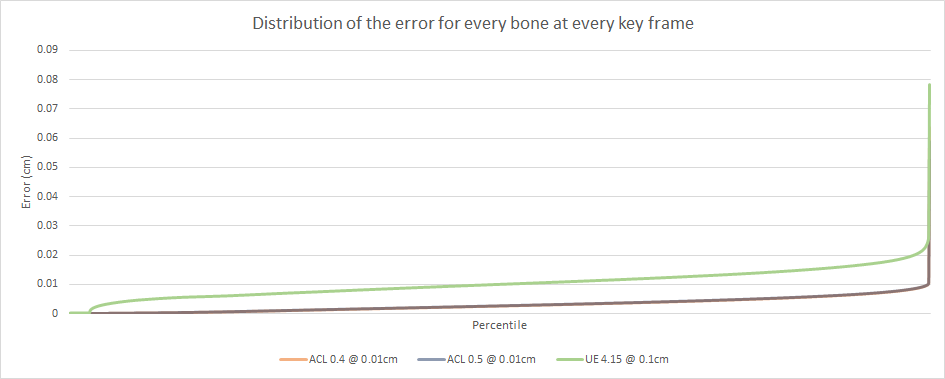
In order to get a full and clear picture, I dumped the error of every bone at every key frame in the original clips. This represents over 37 million samples for the CMU database.
The above image is amazing!
The above two images clearly show how terrible the max clip error is at giving insight into the true error. Here are some numbers visible only in the exhaustive graphs:
ACL crosses the 0.01cm error threshold at the 99.85th percentile (only 0.15% of our values exceed the threshold!)
UE4 @ 0.01cm crosses 0.01cm at the 99.57th percentile, almost just as good
UE4 @ 0.1cm crosses 0.01cm at the 49.8th percentile
UE4 @ 0.1cm crosses 0.02cm at the 98.15th percentile
This clearly shows why 0.1cm might be good enough for production use in Unreal: half our values remain at or below 0.01cm and 98% of the values are below 0.02cm.
The previous images also clearly show how aggressive ACL is at reducing the memory footprint and at maximizing the error up to the error threshold. Therefore, the error threshold must be very conservative, much more so than for Unreal.
Why ACL is re-inventing the wheel
As some have commented in the past, ACL is largely re-inventing the wheel here. As such I will detail the rational for it a bit further.
Writing a whole animation blending middleware such as Granny or Morpheme would not have been practical. Just to match production quality implementations out there would have taken 1+ year part time. Even assuming I could have managed to implement something compelling, the cost of switching to a new animation runtime for a game team is very very high. Animators need to learn new tools and workflow, the engine integration might be tightly coupled, and there is no clear way to migrate old assets to the new format. Middlewares are also getting deprecated increasingly frequently. In that regard, the market has largely spoken: most games released today do so either with one of the major engines (Unreal, Unity, Lumberyard, Stingray, etc.) or large studios such as Activision, Electronic Arts, and Ubisoft routinely have in-house custom engines with their own custom animation runtime. Regardless of the quality or feature set, it would have been highly unlikely that it would ever have been used for something significant.
On the other hand, animation compression is a much smaller problem. Integration is easy: everything is pure C++ headers and most engines out there already support more than one animation compression algorithm. This makes migrating existing assets a trivial task providing the few required features are supported (e.g. 3D scale). Any engine or middleware could integrate ACL with few to no issues to be expected once it is production ready.
Animation compression is also a wheel that NEEDS re-inventing. Of all my blog posts, a single post receives the overwhelming majority of my traffic: animation compression in Unity. Why is it so popular? Because as I mention in said post, accuracy issues will be common in Unity and the memory footprint large for high accuracy settings as a direct result of their error metric. Unity is also not alone, Stingray and Lumberyard both use the same metric. It is a VERY common error metric and it is terrible. Academic papers on this topic are often using different and poor error metrics and show very little to no data to back their results and claims. This makes evaluating these papers for real world usage in games very problematic.
Take this paper for example. They use the CMU database as well. Their error metric uses the leaf bone positions in object/world space as a measure of accuracy. This entirely ignores the rotational error of the leaf bone. They show a single graph of their results and two short tables. They do not detail the data further. Compare this with the wealth of information I was able to pull out and publish here. Even though ACL is much stricter when measuring the error, it is obvious that wavelets fail terribly to compete at the same level of accuracy (which barely makes it in their published findings). Note that they make no mention of what is an acceptable quality level that one might be able to realistically use.
Here is another recent paper published by someone I have met and have great respect for. The paper does not mention which error metric was used to compared against what they had prior nor does it mention how competitive their previous implementation was. It does not publish any concrete data either and only claims that the memory footprint reduces by 65% on average against their previous in-house techniques. It does provide a supplemental video which shows a small curated list of clips along with some statistics but without further information, it is impossible to objectively evaluate how it performs and where it lies on the spectrum of published techniques. Despite these shortcomings, it looks very promising (David knows his stuff!) and I am certainly looking forward to implementing this within ACL.
ACL does not only strive to improve on existing techniques; it will also establish a much-needed baseline to compare against and set a standard for how animation compression should be measured.
Next steps
The results so far clearly show that ACL is one step closer to being production ready. The next few months will focus on bridging that gap towards reaching v1.0.0. In the coming releases, scale support will be added as well as support for other leading platforms. This will be done through a rudimentary Unreal 4 integration to make sure it is tested in a real engine and thus real world settings.
No further effort on my part will be made towards improving the above results until our first production release is made. However, Cody Jones is working on integrating curve key reduction in the meantime.
Special thanks to Cody and Martin Turcotte for their constant feedback and contributions!