Bind pose stripping
23 Jan 2022A little over three years ago, I wrote about storing animation clips relative to the bind pose in order to improve the compression ratio. In a gist, this stores each clip as an additive onto the base bind pose.
This does two things for us:
- It reduces the range of each sub-track (rotation, translation, scale) which allows more accuracy to be retained (e.g. instead of having the pelvis bone animating at 60cm above the root on the ground, it will animate around 0cm relative to the bind position 60cm above said ground).
- It increases the likelihood that sub-tracks will become equal to their identity value as very often joints are not animated and will be equal to their bind pose value. This allows us to remove their values entirely from the compressed byte stream since we only need a bit set to reconstruct them: whether the value is equal to the identity or not.
It is very common for sub-tracks to not be animated and to retain the bind pose value, especially for translations. For example, upper body animations might have all of the lower body be identical to the bind pose. Facial animations might have the rest of the body equal to it. For that reason, at the time, I reported memory savings of up to 8% with that method.
The main drawback of the technique is that in order to reconstruct the clip, we have to apply the output pose onto the bind pose much like we would with an additive clip. This means performing an expensive transform multiplication. With a QVV (quat-vec3-vec3) format, this means performing three quaternion multiplications which isn’t cheap.
However, there is an alternate way to leverage the bind pose to achieve similar memory savings without the expensive overhead: stripping it entirely.
How it works
The Animation Compression Library now allows you to specify per joint what its default value should be. Default values are not stored within the compressed clip and instead rely on a simple bit set.
If a sub-track is not animated, it has a constant value across all its samples. If that constant value is equal to the default value specified, then ACL simply strips it. Later, during decompression, if a sub-track has a default value, we simply write it into the output pose.
ACL is very flexible here and it allows you to specify either a constant value for every default sub-track (e.g. the identity) or you can use a unique value per sub-track (e.g. the bind pose). This way, the full output pose can be safely reconstructed. As a bonus, it also allows default sub-tracks to be skipped entirely. This is very handy when you pre-fill the output pose buffer with the bind pose before decompressing a clip. This can be achieved efficiently with memcpy (or similar) and during decompression default sub-tracks will be skipped, leaving the value untouched in the output pose.
By removing the bind pose, we achieve a very similar result as we would storing the clip as an additive on top of it. We can leverage the fact that many sub-tracks are not animated and are equal to their bind pose value. However, we do not reduce the range of motion.
Crucially, reconstructing the original pose is now much cheaper as it does not involve any expensive arithmetic and the bind pose will often be warm in the CPU cache as multiple clips will use it and it might be used for other things as part of the animation update/evaluation.
Side note: Reducing the range of motion can be partially achieved for translation and scale by simply removing the bind pose value with component wise subtraction. This allows us to reconstruct the original value by adding the bind pose values which is very cheap.
Results
Now that ACL supports this, I measured bind pose stripping against two data sets:
- Carnegie-Mellon University’s motion capture database which contains 2534 clips.
- Paragon which contains 6558 clips.
I measured the final compressed size before and after as well as the 99th percentile error (99% of joint samples have an error below this value):
| CMU | Before | After |
|---|---|---|
| Compressed size | 75.55 MB | 75.50 MB |
| Track error 99th percentile | 0.0088 cm | 0.0088 cm |
For CMU, the small gain is expected due to the nature of motion capture data and bind pose stripping performs about as well as storing clips relative to it. Motion capture is often noisy and sub-tracks are unlikely to be constant, let alone equal to the bind pose.
| Paragon | Before | After |
|---|---|---|
| Compressed size | 224.30 MB | 220.85 MB |
| Track error 99th percentile | 0.0095 cm | 0.0090 cm |
However, for Paragon, the results are 1.54% smaller. It turns out that quite a few clips are adversely impacted by bind pose stripping. They can end up with a size far higher which I found surprising.
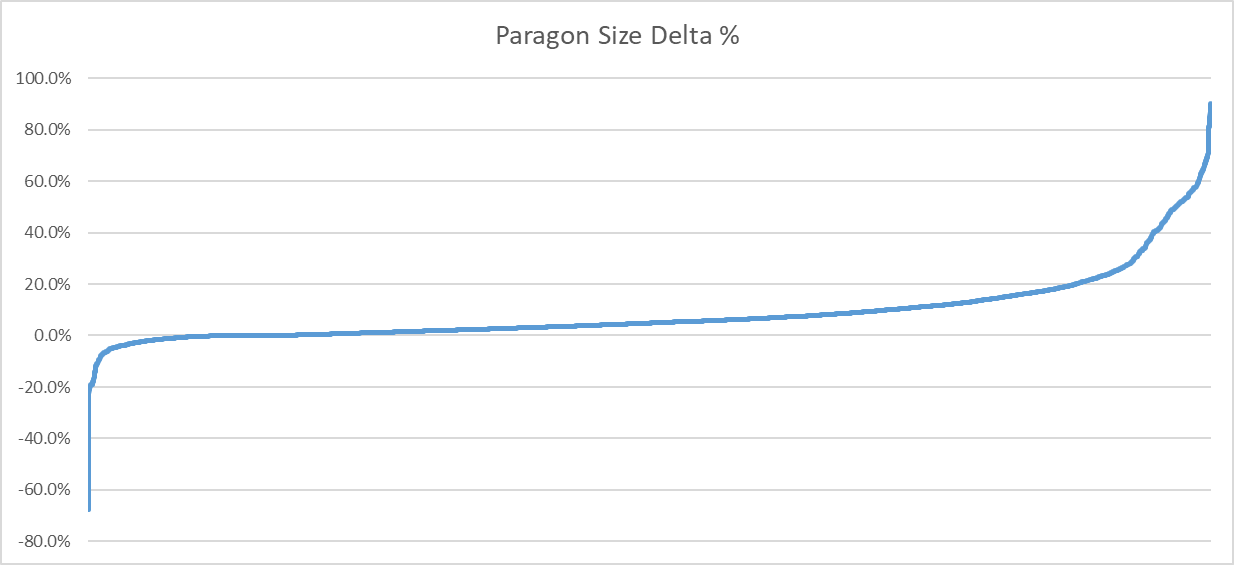
In the above image, I plotted the size delta as a percentage. Positive values denote a reduction in size.
As we can see, for the vast majority of clips, we observe a reduction in size: 5697 (87% of) clips ended up smaller. Over 1889 (29% of) clips saw a reduction of 10% or more. The median represents 4.8% in savings. Not bad!
Sadly, 59 (1% of) clips saw an increase in size of 10% or more with the largest increase at 67.7%.
Looking at some of the clips that perform terribly helped shed some light as to what is going on. Clips that have long bone chains of default sub-track values equal to their bind pose can end up with very high error. To compensate ACL retains more bits to preserve quality. This is caused by two things.
First, we use an error threshold to detect when a sub-track is equal to its default value or not. Even though the error threshold is very conservative, a very small amount of error is introduced and it can compound in long bone chains.
Second, when we measure the compression error, we do so by using the original raw clip. Because the bind pose values we strip rely on the error threshold mentioned above, the optimization algorithm can end up trying to reach a pose that is can never reach. For example, if a joint is stripped by being equal to the bind pose and doing so introduces an error of 1cm on some distant child, even if every joint in between remains with full raw precision values, the error will remain.
Side note, constant sub-tracks use the same error threshold to detect if they are animated or not which can lead to the same issues happening.
This is not easily remedied without some form of error compensation which ACL does not currently support. However, I’m hoping to integrate a partial solution in the coming months. Stay tuned!
Side note, we could pre-process the raw data to ensure that constant and default sub-tracks are clean with every sample perfectly repeating. This would ensure that the error metric does not need to compensate. However, ACL does not own the raw data and as such it cannot do such transformations safely. A future release might expose such functions to clean up the raw data prior to compression.
Conclusion
For the time being I recommend that if you use this new feature, you should also try not stripping the bind pose and pick the best of the two results (for most clips, ACL compresses very fast). The develop branch of the Unreal Engine 4 ACL plugin now supports this experimental feature and testing both codec variations can easily be achieved there (and in parallel too).
Anedoctally, a few people have reached out to me about leveraging this feature and they reported memory savings in the 3-5% range. YMMV.
While the memory savings of this technique aren’t as impressive as storing clips as additives of the bind pose, their dramatically lower decompression cost makes it a very attractive optimization.