29 Jul 2019
A quick recap: animation clips are formed from a set of time series called tracks. Tracks have a fixed number of samples per second and each track has the same length. The Animation Compression Library retains every sample while Unreal Engine uses the popular method of removing samples that can be linearly interpolated from their neighbors.
The first post showed how removing samples negates some of the benefits that come from segmenting, rendering the technique a lot less effective.
The second post explored how sorting (or not) the retained samples impacts the decompression performance.
This third post will take a deep dive into the memory overhead of the three techniques we have been discussing so far:
- Retaining every sample with ACL
- Sorted and unsorted linear sample reduction
Should we remove samples or retain them?
ACL does not yet implement a sample reduction algorithm while UE4 is missing a number of features that ACL provides. As such, in order to keep things as fair as possible, some assumptions will be made for the sample reduction variants and we will thus extrapolate some results using ACL as a baseline.
In order to find out if it is worth it to remove samples and how to best go about storing the remaining samples, we will use the Main Trooper from the Matinee fight scene. It has 541 bones with no animated 3D scale (1082 tracks in total) and the sequence has 1991 frames (~66 seconds long) per track. A total of 71 tracks are constant, 1 is default, and 1010 are animated. Where segmenting is concerned, I use the arbitrarily chosen segment #13 as a baseline. ACL splits this clip in 124 segments of about 16 frames each. This clip has a LOT of data and a high bone count which should highlight how well these algorithms scale.
We will track three things we care about:
- The number of bytes touched during decompression for a full pose
- The number of cache lines touched during decompression for a full pose
- The total compressed size
Due to the simple nature of animation decompression, the number of cache lines touched is a good indicator of overall performance as it often can be memory bound.
All numbers will be rounded up to the nearest byte and cache line.
All three algorithms use linear interpolation and as such require two poses to interpolate our final result.
See the annex at the end of the post for how the math breaks down
The shared base
Some features are always a win and will be assumed present in our three algorithms:
- If a track has a single repeating sample (within a threshold), it will be deemed a constant track. Constant tracks are collapsed into a single full resolution sample with 3x floats (even for rotations) with a single bit per track to tell them apart.
- If a constant track is identical to the identity value for that track type (e.g. quaternion identity), it will be deemed a default track. Default tracks have no sample stored, just a single bit per track to tell them apart.
- All animated tracks (not constant or default) will be normalized within their min/max values by performing range reduction over the whole clip. This increases the accuracy which leads to a lower memory footprint for the majority of clips. To do so, we store our range minimum and extent values as 3x floats each (even for rotations).
The current UE4 codecs do not have special treatment for constant and default tracks but they do support range reduction. There is room for improvement here but that is what ACL uses right now and it will be good enough for our calculations.
| |
Bytes touched |
Cache lines touched |
Compressed size |
| Default bit set |
136 |
3 |
136 bytes |
| Constant bit set |
136 |
3 |
136 bytes |
| Constant values |
852 |
14 |
852 bytes |
| Range values |
24240 |
379 |
24240 bytes |
| Total |
25364 |
399 |
25 KB |
In order to support variable bit rates where each animated track can have its own bit rate, ACL stores 1 byte per animated track (and per segment). This is overkill as only 19 bit rates are currently supported but it keeps things simple and in the future the extra bits will be used for other things. When segmenting is enabled with ACL, range reduction is also performed per segment and adds 6 bytes of overhead per animated track for the quantized range values.
| |
Bytes touched |
Cache lines touched |
Compressed size |
| Bit rates |
1010 |
16 |
123 KB |
| Segment range values |
6060 |
95 |
734 KB |
The ACL results
We will consider two cases for ACL. The default compression settings have segmenting enabled which is great for the memory footprint and compression speed but due to the added memory overhead and range reduction, decompression is a bit slower. As such, we will also consider the case where we disable segmenting in order to bias for faster decompression.
With segmenting, the animated pose size (just the samples, without the bit rate and segment range values) for the segment #13 is 3777 bytes (60 cache lines). This represents about 3.74 bytes per sample or about 30 bits per sample (bps).
Without segmenting, the animated pose size is 5903 bytes (93 cache lines). This represents about 5.84 bytes per sample or about 46 bps.
Although the UE4 codecs do not support variable bit rates the way ACL does, we will assume that we use the same algorithm and as such these numbers of 30 and 46 bits per samples will be used in our projections. Because 30 bps is only attainable with segmenting enabled, we will also assume it is enabled for the sample reduction algorithms when using that bit rate.
| |
Bytes touched |
Cache lines touched |
Compressed size |
| With segmenting |
39990 |
625 |
7695 KB |
| Without segmenting |
38172 |
597 |
11503 KB |
As we can see, while segmenting reduces considerably the overall memory footprint (by 33%), it does contribute to quite a few extra cache lines being touched (4.7% more) during decompression despite the animated pose being 36% smaller. This highlights how normalizing the samples within the range of each segment increases their overall accuracy and reduces the number of bits required to maintain it.
Unsorted sample reduction
In order to decompress when samples are missing, we need to store the sample time (or index). For every track, we will search for the two samples that bound the current time we are interpolating at and reconstruct the correct interpolation alpha from them. To keep things simple, we will store this time value on 1 byte per sample retained (for a maximum of 256 samples per clip or segment) along with the total number of samples retained per track on 1 byte. Supporting arbitrary track decompression efficiently also requires storing an offset map where each track begins. For simplicity’s sake, we will omit this overhead but UE4 uses 4 bytes per track. When decompressing, we will assume that we immediately find the two samples we need within a single cache line and that both samples are within another cache line (2 cache misses per track).
These estimates are very conservative. In practice, the offsets are required to support Levels of Detail as well as efficient single bone decompression and more than 1 byte is often required for sample indices and their count in larger clips. In the wild, the memory footprint is surely going to be larger than these projections will show.
Values below assume every sample is retained, for now.
| |
Bytes touched |
Cache lines touched |
Compressed size |
| Sample times |
2020 |
1010 |
1964 KB |
| Sample count with segmenting |
1010 |
16 |
123 KB |
| Sample values with segmenting |
7575 |
1010 |
7346 KB |
| Total with segmenting |
43039 |
2546 |
10315 KB |
| Sample count without segmenting |
1010 |
16 |
1 KB |
| Sample values without segmenting |
11615 |
1010 |
11470 KB |
| Total without segmenting |
40009 |
2435 |
13583 KB |
When our samples are unsorted, it becomes obvious why decompression is quite slow. The number of cache lines touched is staggering: 2435 cache lines which represents 153 KB! This scales linearly with the number of animated tracks. We can also see that despite the added overhead of segmenting, the overall memory footprint is lower (by 23%) but not by as much as ACL.
Despite my claims from the first post, segmenting appears attractive here. This is a direct result of our estimates being conservative and UE4 not supporting the aggressive per track quantization that ACL provides.
Sorted sample reduction
With our samples sorted, we will add 16 bits of metadata per sample to store the sample time, the track index, and track type. This is optimistic. In reality, some samples would likely require more than that.
Our context will only store animated tracks to keep it as small as possible. We will consider two scenarios: when our samples are stored with full precision (96 bits per sample) and when they are packed with the same format as the compressed byte stream (in which case we simply copy the values into our context when seeking, no unpacking occurs). As previously mentioned, linear interpolation requires us to store two samples per animated track.
| |
Bytes touched |
Cache lines touched |
| Context values @ 96 bps |
24240 |
379 |
| Context values @ 46 bps |
12808 |
198 |
| Context values @ 30 bps |
14626 |
230 |
Right off the bat, it is clear that if we want interpolation to be as fast as possible (with no unpacking), our context is quite large and requires evicting quite a bit of CPU cache. To keep the context footprint as low as possible, going forward we will assume that we store the values packed inside it. Storing packed samples into our context comes with challenges. Each segment will have a different pose size and as such we either need to resize the context or allocate it with the largest pose size. When packed in the compressed byte stream, each sample is often bit aligned and copying into another bit aligned buffer is more expensive than a regular memcpy operation. Keeping the context size low requires some work.
Note that the above numbers also include the bytes touched for the bit rates and segment range values (where relevant) because they are needed for interpolation when samples are packed.
| |
Bytes touched |
Cache lines touched |
Compressed size |
| Compressed values with segmenting |
5798 |
91 |
11274 KB |
| Compressed values without segmenting |
7919 |
123 |
15398 KB |
| Total with segmenting |
45788 |
720 |
12156 KB |
| Total without segmenting |
46091 |
720 |
15424 KB |
Note that the compressed size above does not consider the footprint of the context required at runtime to decompress but the bytes and cache lines touched do.
Compared to the unsorted algorithm, the memory overhead goes up quite a bit: the constant struggle between size and speed.
The number of cache lines touched during decompression is quite a bit higher (15%) than ACL. In order to match ACL, 100% of the samples must be dropped which makes sense considering that we use the same bit rate as ACL to estimate and our context stores two poses which is also what ACL touches. Reading the compressed pose is added on top of this. As such, if every sample is dropped within a pose and already present in our context the decompression cost will be at best identical to ACL since the two will perform about the same amount of work. Reading compressed samples and copying them into our context will take some time and lead to a net win for ACL.
If instead we keep the context at full precision and unpack samples once into it, the picture becomes a bit more complicated. If no unpacking occurs and we simply interpolate from the context, we will be touching more cache lines overall but everything will be very hardware friendly. Decompression is likely to beat ACL but the evicted CPU cache might slow down the caller slightly. Whether this yields a net win is uncertain. Any amount of unpacking that might be required will slow things down further as well. Ultimately, even if enough samples are dropped and it is faster, it will come with a noticeable increase in runtime memory footprint and the complexity to manage a persistent context.
Three challengers enter, only one emerges victorious
| |
Bytes touched |
Cache lines touched |
Compressed size |
| Uniform with segmenting |
39990 |
625 |
7695 KB |
| Unsorted with segmenting |
43039 |
2546 |
10315 KB |
| Sorted with segmenting |
45788 |
720 |
12156 KB |
| Uniform without segmenting |
38172 |
597 |
11503 KB |
| Unsorted without segmenting |
40009 |
2435 |
13583 KB |
| Sorted without segmenting |
46091 |
720 |
15424 KB |
ACL retains every sample and touches the least amount of memory and it applies the lower CPU cache pressure. However, so far our estimates assumed that all samples were retained and as such, we cannot make a determination as to whether or not it also wins on the overall memory footprint. What we can do however, is determine how many samples we need to drop in order to match it.
With unsorted samples, we have to drop roughly 30% of our samples in order to match the compressed memory footprint of ACL with segmenting and 15% without. However, regardless of how many samples we remove, the decompression performance will never come close to the other two techniques due to the extremely high number of cache misses.
With sorted samples, we have to drop roughly 40% of our samples in order to match the compressed memory footprint of ACL with segmenting and 25% without. The number of cache lines touched during decompression is now quite a bit closer to ACL compared to the unsorted algorithm. It may or may not end up being faster to decompress depending on how many samples are removed, the context format used, and how many samples need unpacking but it will always evict more of the CPU cache.
It is worth noting that most of these numbers remain true if cubic interpolation is used instead. While the context object will double in size and thus require more cache lines to be touched during decompression, the total compressed size will remain the same if the same number of samples are retained.
The fourth and last blog post in the series will look at how many samples are actually removed in Paragon and Fortnite. This will complete the puzzle and paint a clear picture of the strengths and weaknesses of linear sample reduction techniques.
Annex
Inputs:
num_segments = 124num_samples_per_track = 1991num_tracks = 1082num_animated_tracks = 1010num_constant_tracks = 71bytes_per_sample_with_segmenting = 3.74bytes_per_sample_without_segmenting = 5.84num_animated_samples = num_samples_per_track * num_animated_tracks = 2010910num_pose_to_interpolate = 2
Shared math:
bitset_size = num_tracks / 8 = 136 bytesconstant_values_size = num_constant_tracks * sizeof(float) * 3 = 852 bytesrange_values_size = num_animated_tracks * sizeof(float) * 6 = 24240 bytesclip_shared_size = bitset_size * 2 + constant_values_size + range_values_size = 25364 bytes = 25 KBbit_rates_size = num_animated_tracks * 1 = 1010 bytesbit_rates_size_total_with_segmenting = bit_rates_size * num_segments = 123 KBsegment_range_values_size = num_animated_tracks * 6 = 6060 bytessegment_range_values_size_total = segment_range_values_size * num_segments = 734 KBanimated_pose_size_with_segmenting = bytes_per_sample_with_segmenting * num_animated_tracks = 3778 bytesanimated_pose_size_without_segmenting = bytes_per_sample_without_segmenting * num_animated_tracks = 5899 bytes
ACL math:
acl_animated_size_with_segmenting = animated_pose_size_with_segmenting * num_samples_per_track = 7346 KBacl_animated_size_without_segmenting = animated_pose_size_without_segmenting * num_samples_per_track = 11470 KBacl_decomp_bytes_touched_with_segmenting = clip_shared_size + bit_rates_size + segment_range_values_size + acl_animated_pose_size_with_segmenting * num_pose_to_interpolate = 39990 bytesacl_decomp_bytes_touched_without_segmenting = clip_shared_size + bit_rates_size + acl_animated_pose_size_without_segmenting * num_pose_to_interpolate = 38172 bytesacl_size_with_segmenting = clip_shared_size + bit_rates_size_total_with_segmenting + segment_range_values_size_total + acl_animated_size_with_segmenting = 8106 KB (actual size is lower due to the bytes per sample changing from segment to segment)acl_size_without_segmenting = clip_shared_size + bit_rates_size + acl_animated_size_without_segmenting = 11496 KB (actual size is higher by a few bytes due to misc. clip overhead)
Unsorted linear sample reduction math:
unsorted_decomp_bytes_touched_sample_times = num_animated_tracks * 1 * num_pose_to_interpolate = 1010 bytesunsorted_sample_times_size_total = num_animated_samples * 1 = 1964 KBunsorted_sample_counts_size = num_animated_tracks * 1 = 1010 bytesunsorted_sample_counts_size_total = unsorted_sample_counts_size * num_segments = 123 KBunsorted_animated_size_with_segmenting = acl_animated_size_with_segmenting = 7346 KBunsorted_animated_size_without_segmenting = acl_animated_size_without_segmenting = 11470 KBunsorted_total_size_with_segmenting = clip_shared_size + bit_rates_size_total_with_segmenting + segment_range_values_size_total + unsorted_sample_times_size_total + unsorted_sample_counts_size_total + unsorted_animated_size_with_segmenting = 10315 KBunsorted_total_size_without_segmenting = clip_shared_size + bit_rates_size_total + unsorted_sample_times_size_total + unsorted_sample_counts_size + unsorted_animated_size_without_segmenting = 13583 KBunsorted_total_sample_size_with_segmenting = unsorted_sample_times_size_total + unsorted_animated_size_with_segmenting = 9310 KBunsorted_total_sample_size_without_segmenting = unsorted_sample_times_size_total + unsorted_animated_size_without_segmenting = 13434 KBunsorted_drop_rate_with_segmenting = (unsorted_total_size_with_segmenting - acl_size_with_segmenting) / unsorted_total_sample_size_with_segmenting = 28 %unsorted_drop_rate_without_segmenting = (unsorted_total_size_without_segmenting - acl_size_without_segmenting) / unsorted_total_sample_size_without_segmenting = 15.5 %
Sorted linear sample reduction math:
full_resolution_context_size = num_animated_tracks * num_pose_to_interpolate * sizeof(float) * 3 = 24240 bytes = 24 KBwith_segmenting_context_size = num_pose_to_interpolate * animated_pose_size_with_segmenting = 7556 byteswithout_segmenting_context_size = num_pose_to_interpolate * animated_pose_size_without_segmenting = 11798 byteswith_segmenting_context_decomp_bytes_touched = with_segmenting_context_size + bit_rates_size + segment_range_values_size = 14626 bytes = 15 KBwithout_segmenting_context_decomp_bytes_touched = without_segmenting_context_size + bit_rates_size = 12808 bytes = 13 KBsorted_decomp_compressed_bytes_touched_with_segmenting = num_animated_tracks * sizeof(uint16) + animated_pose_size_with_segmenting = 5798 bytessorted_decomp_compressed_bytes_touched_without_segmenting = num_animated_tracks * sizeof(uint16) + animated_pose_size_without_segmenting = 7919 bytessorted_animated_size_with_segmenting = num_animated_samples * sizeof(uint16) + acl_animated_size_with_segmenting = 11274 KBsorted_animated_size_without_segmenting = num_animated_samples * sizeof(uint16) + acl_animated_size_without_segmenting = 15398 KBsorted_decomp_bytes_touched_with_segmenting = with_segmenting_context_decomp_bytes_touched + sorted_decomp_compressed_bytes_touched_with_segmenting + clip_shared_size = 45788 bytes = 45 KBsorted_decomp_bytes_touched_without_segmenting = without_segmenting_context_decomp_bytes_touched + sorted_decomp_compressed_bytes_touched_without_segmenting + clip_shared_size = 46091 bytes = 46 KBsorted_total_size_with_segmenting = clip_shared_size + bit_rates_size_total_with_segmenting + segment_range_values_size_total + sorted_animated_size_with_segmenting = 12156 KBsorted_total_size_without_segmenting = clip_shared_size + bit_rates_size + sorted_animated_size_without_segmenting = 15424 KBsorted_drop_rate_with_segmenting = (sorted_total_size_with_segmenting - acl_size_with_segmenting) / sorted_animated_size_with_segmenting = 40 %sorted_drop_rate_without_segmenting = (sorted_total_size_without_segmenting - acl_size_without_segmenting) / sorted_animated_size_without_segmenting = 25.5 %
25 Jul 2019
A quick recap: animation clips are formed from a set of time series called tracks. Tracks have a fixed number of samples per second and each track has the same length. The Animation Compression Library retains every sample while the most commonly used Unreal Engine codecs use the popular method of removing samples that can be linearly interpolated from their neighbors.
The first post showed how removing samples negates some of the benefits that come from segmenting, rendering the technique a lot less effective.
Another area where it struggles is decompression performance. When we want to sample a clip at a particular point in time, we have to search and find the closest samples in order to interpolate them. Unreal Engine lays out the data per track: the indices for all the retained samples are followed by their sample values.
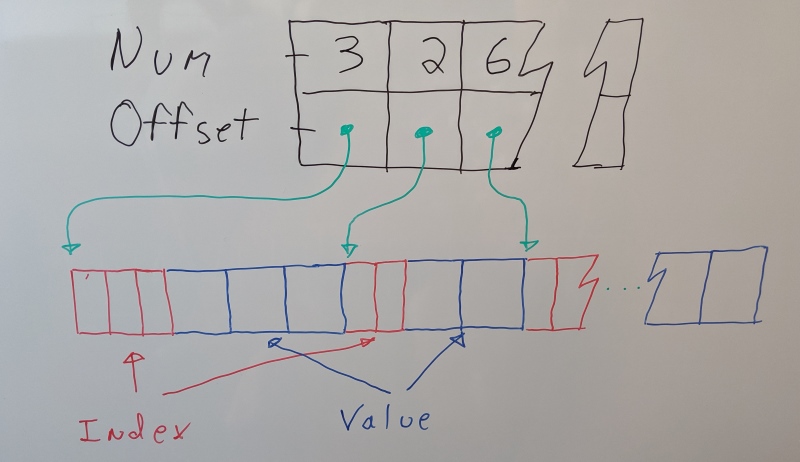
This comes with a major performance drawback: each track will incur a cache miss for the sample indices in order to find the neighbors and another cache miss to read the two samples we need to interpolate. This is very slow. Each memory access will be random, preventing the hardware prefetcher from hiding the memory access latency. Even if we manage to prefetch it by hand, we still touch a very large number of cache lines. Equally worse, each cache line is only used partially as they also contain data we will not need. In the end, a significant portion of our CPU cache will be evicted with data that will only be read once.

In contrast, ACL retains every sample and sorts them by time (sample index). This ensures that all the samples we need at a particular point in time are contiguous in memory. Sampling our clip becomes very fast:
- We don’t need to search for our neighbors, just where the first sample lives
- We don’t need to read indices, offsets, or the number of samples retained
- Each cache line is fully used
- The hardware prefetcher will detect our predictable access pattern and work properly
Sorting is clearly the key to fast decompression.
Sorting retained samples
Back in 2017, if you searched for ‘‘animation compression’’, the most popular blog posts were one by Bitsquid which advocates using curve fitting with sorted samples for fast and cache friendly decompression and a post by Riot Games about trying the same technique with some success.
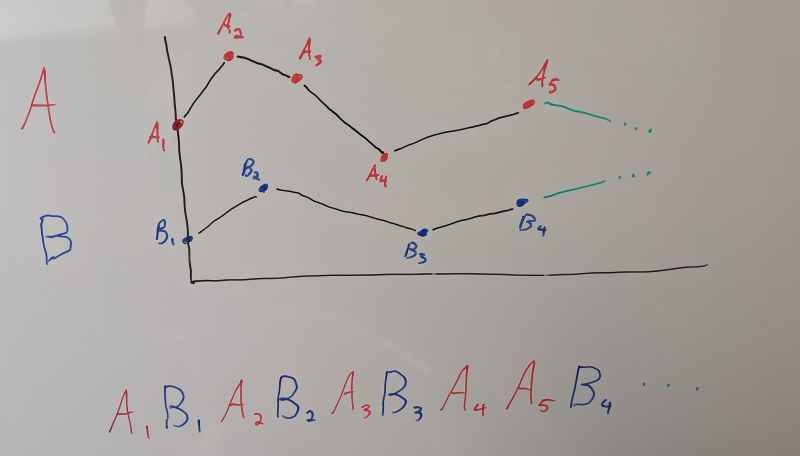
Without getting into the details too much (the two posts above explain it quite well), you sort the samples by the time you need them at (NOT by their sample time) and you keep track from frame to frame where and what you last decompressed from the compressed byte stream. Once decompressed, samples are stored (often raw, unpacked) in a persistent context object that is reused from frame to frame. This allows you to touch the least possible amount of compressed contiguous data every frame by unpacking only the new samples that you need to interpolate at the current desired time. Once all your samples are unpacked inside the context, interpolation is very fast. You can use tons of tricks like Structure of Arrays, wider SIMD registers with AVX, and you can easily interpolate two or three samples at a time in order to use all available registers and minimize pipeline stalls. This requires keeping a context object around all the time but it is by far the fastest way to interpolate a compressed animation because you can avoid unpacking samples that have already been cached.
Sorting our samples keeps things contiguous and CPU cache friendly and as such it stood to reason that it was a good idea worth trying. Some Unreal Engine codecs already support linear sample reduction and as such the remaining samples were simply sorted in the same manner.
With this new technique, decompression was up to 4x faster on PC. It looked phenomenal in a gym.
Unfortunately, this technique has a number of drawbacks that are either skimmed briefly, downplayed, or not mentioned at all in the two blog posts advocating it. Those proved too significant to ignore in Fortnite. Sometimes being the fastest isn’t the best idea.
No U-turn allowed
By sorting the samples, the playback direction must now match the sort direction. If you attempt to play a sequence backwards that has its samples sorted forward, you must seek and read everything until you find the ones you need. You can sort the samples backwards to fix this but forward playback will now have the same issue. There is no optimal sort order for both playback directions. Similarly, random seeks in a sequence have equally abysmal performance.
As Bitsquid mentions, this can be mitigated by introducing a full frame of data at specific intervals to avoid fully reading everything or segments can be used for the same purpose. This comes at the cost of a larger memory footprint and it does not offset entirely the extra work done when seeking. One would think that most clips play forward in time and it isn’t that big a deal. Sure some clips play backward or randomly but those aren’t that common, right?
In practice, things are not always this way. Many prop animations will play forward and backward at runtime. For example, a chest opening and closing might have a single animation played in both directions. The same idea can be used with all sorts of other objects like doors, windows, etc. A more subtle problem are clips that play forward in time but that do not start playing at the beginning. With motion matching, often when you transition from one clip to another you will not start playing the new clip at frame 0. When playback starts, you will have to read and skip samples, creating a performance spike. This can also happen with clips that advance in time but do not decompress due to Level of Detail (LOD) constraints. As soon as those characters start animating, performance spikes. It is also worth noting that even if you start playing at the first frame, you need to unpack everything needed to prime the context which creates a performance spike regardless.
30 FPS is ‘more cinematic’
It is not unusual for clips to be exported with varying sample rates such as 30, 60, or 120 FPS (and everything in between). Equally common are animations that play at various rates. However, unlike other techniques, these properties combine and can become problematic. If we play an animation faster than its sample rate (e.g. a 60 FPS game with 30 FPS animations) we will have frames where no data needs to be unpacked from the compressed stream and we can interpolate entirely from the context. This is very fast but it does mean that our decompression performance is inconsistent as some frames will need to unpack samples while others will not. This typically isn’t that big a deal but things get much worse if we play back slower than the sample rate (e.g. a 30 FPS game with 60 FPS animations). Our clip contains many more samples that we will not need to interpolate and because they are sorted, we will have to read and skip them in order to reach the ones we need. When samples are removed and sorted, decompression performance becomes a function of the playback speed and the animation sample rate. Such a problematic scenario can arise if an animation (such as a cinematic) requires a very high sample rate to maintain its quality (perhaps due to cloth and hair simulations).
Just one please
Although not as common, single bone decompression performance is pretty bad. Because all the data is mixed together, decompressing a specific bone requires decompressing (or at least skipping) all the other data. This is fine if you rarely do it or if it’s done at the same time as sampling the full pose while sharing the context between calls but this is not always possible. In some cases you have to sample individual bones at runtime for various gameplay or AI purposes (e.g. to predict where a bone will land in the future). This same property of the data means that lowering the LOD does not speed up seeking nor does it reduce the context memory footprint as everything needs to be unpacked just in case the LOD changes suddenly (although you can get away with interpolating only what you need).
One more byte
Just one more bite
Sorting the samples means that there is no pattern to them and metadata per sample needs to be introduced. You need to be able to tell what type a sample is (rotation, translation, 3D scale, scalar), at what time the sample appears, and which bone it belongs to. This overhead being per sample adds up quickly. You can use all sorts of clever tricks to use fewer bits if the bone index and sample time index are small compared to the previous one but ultimately it is quite a bit larger than alternative techniques and it cannot be hidden or removed entirely.
With all of this data, the context object becomes quite large to the point where its memory footprint cannot be ignored in a game with many animations playing at the same time. In order to interpolate, you need at least two full poses with linear interpolation (four if you use cubic curves) stored inside along with other metadata to keep track of things. For example, if a bone transform needs a quaternion (rotation) and a vector3 (translation) for a total of 28 bytes, 100 bones will require 2.7 KB for a single pose and 5.5 KB for two (and often 3D scale is needed, adding even more data). With curves, those balloon to 11 KB and by touching them you evict over 30% of your CPU L1 cache (most CPUs have 32 KB of L1) for data that will not be needed again until the next frame. This is not cheap.
It is clear that while we touch less compressed memory and avoid the price of unpacking it, we end up accessing quite a bit of uncompressed memory, evicting precious CPU cache lines in the process. Typically, once decompression ends, the resulting pose will be blended with another intermediate pose later to be blended with another, and another. All of these intermediate poses benefit from remaining in the cache because they are needed over and over often reused by new decompression and pose blending calls. As such, the true cost of decompression cannot be measured easily: the cache impact can slow down the calling code as well. While sorting is definitely more cache friendly than not doing so when samples are removed, whether this is more so than retaining every sample is not as obvious.
You can keep the poses packed in some way within the context, either with the same format as the compressed stream or packed in a friendlier format at the cost of interpolation performance. Regardless, the overhead adds up and in a game like Fortnite where you can have 50 vs 50 players fighting with props, pets, and other things animating all at the same time, the overall memory footprint ended up too large to be acceptable on mobile devices. We attempted to not retain a context object per animation that was playing back, sharing them across characters and threads but this added a lot of complexity and we still had performance spikes from the higher amount of seeking. You can have a moderate amount of expensive seeks or a lower runtime memory footprint but not both.
This last point ended up being an issue even without any sorting (just with segmenting). Even though the memory overhead was not as significant, it still proved to be above what we would have liked, the complexity too high, and the decompression performance too unpredictable.
A lot of complexity for not much
Overall, sorting the samples retained increased slightly the compressed size, it increased the runtime memory footprint, decompression performance became erratic, while peak decompression speed increased. Overcoming these issues would have required a lot more time and effort. With the complexity already being very high, I was not confident I could beat the unsorted codecs consistently. We ultimately decided not to use this technique. The runtime memory footprint increased beyond what we considered acceptable for Fortnite and the decompression performance too erratic.
Although the technique appeared very attractive as presented by Bitsquid, it ended up being quite underwhelming. This was made all the more apparent by my parallel efforts with ACL that retained every sample yet achieved remarkable results with little to no complexity. ACL has consistent and fast decompression performance regardless of the playback rate, playback direction, or sample rate and it does this without the need for a persistent context.
When linear sample reduction is used, both sorted and unsorted algorithms have significant drawbacks when it comes to decompression performance and memory usage. While both techniques require extra metadata that increases their memory footprint, if enough samples are removed, the overhead can be offset to yield a net win. The next post will look into how many samples need to be removed in order to beat ACL which retains all of them.
23 Jul 2019
Two years ago I worked with Epic to try to improve the Unreal Engine animation compression codecs. While I managed to significantly improve the compression performance, despite my best intentions, a lot of research, and hard work, some of the ideas I tried failed to improve the decompression speed and memory footprint. In the end their numbers just didn’t add up when working at the scale Fortnite operates at.
I am now refactoring Unreal’s codec API to natively support animation compression plugins. As part of that effort, I am removing the experimental ideas I had added and I thought they deserved their own blog posts. There are many academic papers and posts about things that worked but very few about those that didn’t.
The UE4 codecs rely heavily on linear sample reduction: samples in a time series that can be linearly interpolated from their neighbors are removed to achieve compression. This technique is very common but it introduces a number of nuances that are often overlooked. We will look at some of these in this multi-part series:
TL;DR: As codecs grow in complexity, they can sometimes have unintended side-effects and ultimately be outperformed by simpler codecs.
What we are working with?
Animation data consists of a series of values at various points in time (a time series). These drive the rotation, translation, and scale of various bones in a character’s skeleton or in some object (prop). Both Unreal Engine and the Animation Compression Library work with a fixed number of samples (frames) per second. Storing animation curves where the samples can be placed at arbitrary points in time isn’t as common in video games. The series of rotation, translation, and scale are called tracks and all have the same length. Together they combine to form an animation clip that describes how multiple bone transforms evolve over time.
Compression is commonly achieved by:
- Removing samples that can be reconstructed by interpolating between the remaining neighbors
- Storing each sample using a reduced number of bits
Unreal Engine uses linear interpolation to reconstruct the samples it removes and it stores each track using 32, 48, or 96 bits per sample.
ACL retains every sample and stores each track using 9, 12, 16, … 96 bits per sample (19 possible bit rates).
Slice it up!
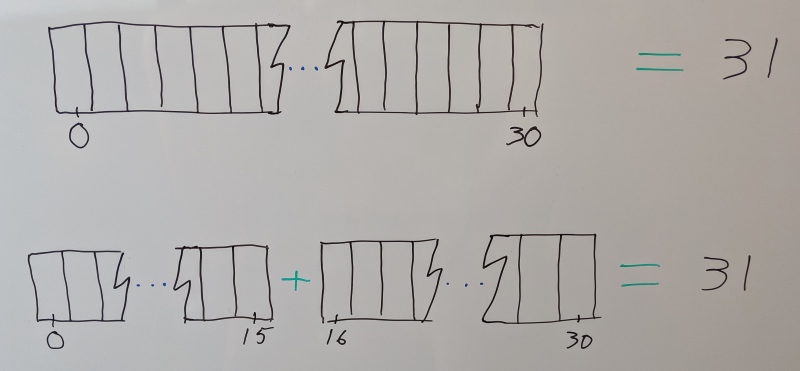
Segmenting a clip is the act of splitting it into a number of independent and contiguous segments. For example, we can split an animation sequence that has tracks with 31 samples each (1 second at 30 samples per second) into two segments with 16 and 15 samples per track.
Segmenting has a number of advantages:
- Values within a segment have a reduced range of motion which allows fewer bits to be used to represent them, achieving compression.
- When samples are removed we have to search for their neighbors to reconstruct their value. Segmenting allows us to narrow down the search faster, reducing the cost of seeking.
- Because all the data needed to sample a time
T is within a contiguous segment, we can easily stream it from a slower medium or prefetch it.
- If segments are small enough, they fit entirely within the processor L1 or L2 cache which leads to faster compression.
- Independent segments can trivially be compressed in parallel.
Around that time in the summer of 2017, I introduced segmenting into ACL and saw massive gains: the memory footprint reduced by roughly 36%.
ACL uses 16 samples per segment on average and having access to the animations from Paragon I looked at how many segments it had: 6558 clips turned into 49214 segments.
What a great idea to try with the UE4 codecs as well!
Segmenting in Unreal
Unfortunately, the Unreal Engine codecs were not designed with this concept in mind.
In order to keep decompression fast, each track stores an offset into the compressed byte stream where its data starts as well as the number of samples retained. This allows great performance if all you need is a single bone or when bones are decompressed in an order different from the one they were compressed in (this is quite common in UE4 for various reasons).
Unfortunately, this overhead must be repeated in every segment. To avoid the compressed clip’s size increasing too much, I settled on a segment size of 64 samples. But these larger segments came with some drawbacks:
- They are less likely to fit in the CPU L1 cache when compressing
- There are fewer opportunities for parallelism when compressing
- They don’t narrow the sample search as much when decompressing
Most of the Paragon clips are short. Roughly 60% of them need only a single segment. Only 19% had more than two segments. This meant most clips consumed the same amount of memory while being slightly slower to decompress. Only long cinematics like the Matinee fight scene showed significant gains on their memory footprint, compression performance, and decompression performance. In my experience working on multiple games, short clips are by far the most common and Paragon isn’t an outlier.
Overall, segmenting worked but it was very underwhelming within the UE4 codecs. It did not deliver what I had hoped it would and what I had seen with ACL.
In an effort to fix the decompression performance regression, a context object was introduced, adding even more complexity. A context object persists from frame to frame for each clip being played back. It allows data to be reused from a previous decompression call to speed up the next call. It is also necessary in order to support sorting the samples which I tried next and will be covered in my next post.
14 Jun 2019
Ever since the Animation Compression Library UE4 Plugin was released in July 2018, I have been comparing and tracking its progress against Unreal Engine 4.19.2. For the sake of consistency, even when newer UE versions came out, I did not integrate ACL and measure from scratch. This was convenient and practical since animation compression doesn’t change very often in UE and the numbers remain fairly close over time. However, in UE 4.21 significant changes were made and comparing against an earlier release was no longer a fair and accurate comparison.
As such, I have updated my baseline to UE 4.22.2 and am releasing a new version of the plugin to go along with it: v0.4. This new plugin release does not bring significant improvements on the previous one (they both still use ACL v1.2) but it does bring the necessary changes to integrate cleanly with the newer UE API. One of the most notable changes in this release is the introduction of git patches for the custom engine changes required to support the ACL plugin. Note that earlier engine versions are not officially supported although if there is interest, feel free to reach out to me.
One benefit of the thorough measurements that I regularly perform is that not only can I track ACL’s progress over time but I can also do the same with Unreal Engine. Today we’ll talk about Unreal a bit more.
What changed in UE 4.21
Two years ago Epic asked me to improve their own animation compression. The primary focus was on improving the compression speed of their automatic compression codec while maintaining the existing memory footprint and decompression speed. Improvements to the other metrics was considered a stretch goal.
The automatic compression codec in UE 4.20 and earlier tried 35+ codec permutations and picked the best overall. Understandably, this could be quite slow in many cases.
To speed it up, two important changes were made:
- The codecs tried were distilled into a white list of the 11 most commonly used codecs
- The codecs are now evaluated in parallel
This brought a significant win. As mentioned at the Games Developer Conference 2019, the introduction of the white list brought the time to compress Fortnite (while cooking for the Xbox One) from 6h 25mins down to 1h 50mins, a speed up of 3.5x. Executing them in parallel lowered this even more, down to 40mins or about 2.75x faster. Overall, it ended up 9.6x faster.
While none of this impacted the codecs or the API in any way, UE 4.21 also saw significant changes to the codec API. The reason for this will be the subject of my next blog post: failed optimization attempts and the lessons learned from them. In particular, I will show why removing samples that can be reconstructed through interpolation has significant drawbacks. Sometimes despite your best intentions and research, things just don’t pan out.
The juicy numbers
For the GDC presentation we only measured a few metrics and only while cooking Fortnite. However, every release I use a much more extensive set of animations to track progress and many more metrics. Here are all the numbers.
Note: The ACL plugin v0.3 numbers are from its integration in UE 4.19.2 while v0.4 is with UE 4.22.2. Because the Unreal codecs didn’t change, the decompression performance remained roughly the same. The ACL plugin accuracy numbers are slightly different due to fixes in the commandlet used to extract them. The compression speedup for the ACL plugin largely comes from the switch to Visual Studio 2017 that came with UE 4.20.
For details about this data set and the metrics used, see here.
| |
ACL Plugin v0.4.0 |
ACL Plugin v0.3.0 |
UE v4.22.2 |
UE v4.19.2 |
| Compressed size |
74.42 MB |
74.42 MB |
100.15 MB |
99.94 MB |
| Compression ratio |
19.21 : 1 |
19.21 : 1 |
14.27 : 1 |
14.30 : 1 |
| Compression time |
5m 10s |
6m 24s |
11m 11s |
1h 27m 40s |
| Compression speed |
4712 KB/sec |
3805 KB/sec |
2180 KB/sec |
278 KB/sec |
| Max ACL error |
0.0968 cm |
0.0702 cm |
0.1675 cm |
0.1520 cm |
| Max UE4 error |
0.0816 cm |
0.0816 cm |
0.0995 cm |
0.0996 cm |
| ACL Error 99th percentile |
0.0089 cm |
0.0088 cm |
0.0304 cm |
0.0271 cm |
| Samples below ACL error threshold |
99.90 % |
99.93 % |
47.81 % |
49.34 % |
For details about this data set and the metrics used, see here.
| |
ACL Plugin v0.4.0 |
ACL Plugin v0.3.0 |
UE v4.22.2 |
UE v4.19.2 |
| Compressed size |
234.76 MB |
234.76 MB |
380.37 MB |
392.97 MB |
| Compression ratio |
18.22 : 1 |
18.22 : 1 |
11.24 : 1 |
10.88 : 1 |
| Compression time |
23m 58s |
30m 14s |
2h 5m 11s |
15h 10m 23s |
| Compression speed |
3043 KB/sec |
2412 KB/sec |
582 KB/sec |
80 KB/sec |
| Max ACL error |
0.8623 cm |
0.8623 cm |
0.8619 cm |
0.8619 cm |
| Max UE4 error |
0.8601 cm |
0.8601 cm |
0.6424 cm |
0.6424 cm |
| ACL Error 99th percentile |
0.0100 cm |
0.0094 cm |
0.0438 cm |
0.0328 cm |
| Samples below ACL error threshold |
99.00 % |
99.19 % |
81.75 % |
84.88 % |
For details about this data set and the metrics used, see here.
| |
ACL Plugin v0.4.0 |
ACL Plugin v0.3.0 |
UE v4.22.2 |
UE v4.19.2 |
| Compressed size |
8.77 MB |
8.77 MB |
23.67 MB |
23.67 MB |
| Compression ratio |
7.11 : 1 |
7.11 : 1 |
2.63 : 1 |
2.63 : 1 |
| Compression time |
16s |
20s |
9m 36s |
54m 3s |
| Compression speed |
3790 KB/sec |
3110 KB/sec |
110 KB/sec |
19 KB/sec |
| Max ACL error |
0.0588 cm |
0.0641 cm |
0.0426 cm |
0.0671 cm |
| Max UE4 error |
0.0617 cm |
0.0617 cm |
0.0672 cm |
0.0672 cm |
| ACL Error 99th percentile |
0.0382 cm |
0.0382 cm |
0.0161 cm |
0.0161 cm |
| Samples below ACL error threshold |
94.61 % |
94.52 % |
94.23 % |
94.22 % |
Conclusion and what comes next
Overall, the new parallel white list is a clear winner. It is dramatically faster to compress and none of the other metrics measurably suffered. However, despite this massive improvement ACL remains much faster.
For the past few months I have been working with Epic to refactor the engine side of things to ensure that animation compression plugins are natively supported by the engine. This effort is ongoing and will hopefully land soon in an Unreal Engine near you.
08 May 2019
Over the years, I picked up a number of tricks to optimize code. Today I’ll talk about one of them.
I first picked it up a few years ago when I was tasked with optimizing the cloth simulation code in Shadow of the Tomb Raider. It had been fine tuned extensively with PowerPC intrinsics for the Xbox 360 but its performance was lacking on XboxOne (x64). While I hoped to talk about it 2 years ago, I ended up side tracked with the Animation Compression Library (ACL). However, last week while introducing ARM64 fused muptiply-add support into ACL and the Realtime Math (RTM) library, I noticed an opportunity to use this trick when linearly interpolating quaternions and it all came back to me.
TL;DR: Flipping the sign of some arithmetic operations can lead to shorter and faster assembly.
Flipping for fun and profit on x64
To understand how this works, we need to give a bit of context first.
On PowerPC, ARM, and many other platforms, before an instruction can use a value it must first be loaded from memory into a register explicitly with a load type instruction. This is not always the case with x86 and x64 where many instructions can take either a register or a memory address as input. In the later case, the load still happens behind the scenes and while it isn’t really much faster by itself it does have a few benefits.
Not having an explicit load instruction means that we do not use one of the precious named registers. While under the hood the CPU has tons of registers (e.g modern processors have 50+ XMM registers), the instructions can only reference a few of them: only 16 named XMM registers can be referenced. This can be very important if a piece of code places considerable pressure on the amount of registers it needs. Fewer named registers used means a reduced likelihood that registers have to spill on the stack and spilling introduces quite a few instructions as well. Altogether, removing that single load instruction can considerably improve the chances of a function getting inlined.
Fewer instructions also means a lower code cache footprint and better overall performance although in practice, I have found this impact very hard to measure.
Two things are important to keep in mind:
- An instruction that operates directly from memory will be slower than the same instruction working from a register: it has to perform the load operation and even if the value resides in the CPU cache, it still takes time.
- Most arithmetic instructions that take two inputs only support having one of them come from memory: addition, subtraction, multiplication, etc. Typically, only the second input (on the right) can come from memory.
To illustrate how flipping the sign of arithmetic operations can lead to improved code generation, we will use the following example:
Both MSVC 19.20 and GCC 9 generate the above assembly. The 1.0f constant must be loaded from memory because subss only supports the second argument coming from memory. Interestingly, Clang 8 figures out that it can use the sign flip trick all on its own:
Because we multiply our input value by a constant, we are in control of its sign and we can leverage that fact to change our subss instruction into an addss instruction that can work with another constant from memory directly. Both functions are mathematically equivalent and their results are identical down to every last bit.
Short and sweet!
Not every mainstream compiler today is smart enough to do this on its own especially in more complex cases where other instructions will end up in between the two sign flips. Doing it by hand ensures that they have all the tools to do it right. Should the compiler think that performance will be better by loading the constant into a register anyway, it will also be able to do so (for example if the function is inlined in a loop).
But wait, there’s more!
While that trick is very handy on x64, it can also be used in a different context and I found a good example on ARM64: when linearly interpolating quaternions.
Typically linear interpolation isn’t recommended with quaternions as it is not guaranteed to give very accurate results if the two quaternions are far apart. However, in the context of animation compression, successive quaternions are often very close to one another and linear interpolation works just fine. Here is what the function looked like before I used the trick:
The code is fairly simple:
- We calculate a bias and if both quaternions are on opposite sides of the hypersphere (negative dot product), we apply a bias to flip one of them to make sure that they lie on the same side. This guarantees that the path taken when interpolating will be the shortest.
- We linearly interpolate:
(end - start) * alpha + start
- Last but not least, we normalize our quaternion to make sure that it represents a valid 3D rotation.
When I introduced the fused multiply-add support to ARM64, I looked at the above code and its generated assembly and noticed that we had a multiplication instruction followed by a subtraction instruction before our final fused multiply-add instruction. Can we do better?
While FMA3 has a myriad of instructions for all sorts of fused multiply-add variations, ARM64 does not: it only has 2 such instructions: fmla ((a * b) + c) and fmls (-(a * b) + c).
Here is the interpolation broken down a bit more clearly:
x = (end * bias) - start (fmul, fsub)result = (x * alpha) + start (fmla)
After a bit of thinking, it becomes obvious what the solution is:
-x = -(end * bias) + start (fmls)result = -(-x * alpha) + start (fmls)
By flipping the sign of our intermediate value with the fmls instruction, we can flip it again and cancel it out by using it once more while removing an instruction in the process. This simple change resulted in a 2.5 % speedup during animation decompression (which also does a bunch of other stuff) on my iPad.
Note: because fmls reuses one of the input registers for its output, a new mov instruction was added in the final inlined decompression code but it executes much faster than a floating point instruction.
You can find the change in RTM here.