Compressing looping animation clips
03 Apr 2022Animations that loop have a unique property in that the last character pose must exactly match the first, for playback to be seamless as they wrap around. As a result, this means that the repeating first/last pose is redundant. Looping animations are fairly common, and it thus makes sense to try and leverage this in order to reduce the memory footprint. However, there are important caveats with this, and special care must be taken.
The Animation Compression Library now supports two looping modes: clamp and wrap.
To illustrate things, I will use a simple 1D repeating sequence but in practice, everything can be generalized in 3D (e.g. translations), 4D (e.g. rotation quaternions), and other dimensions.
Clamping loops
Clamping requires the first and last samples to match exactly, and both will be retained in the final compressed data. This keeps things very simple.
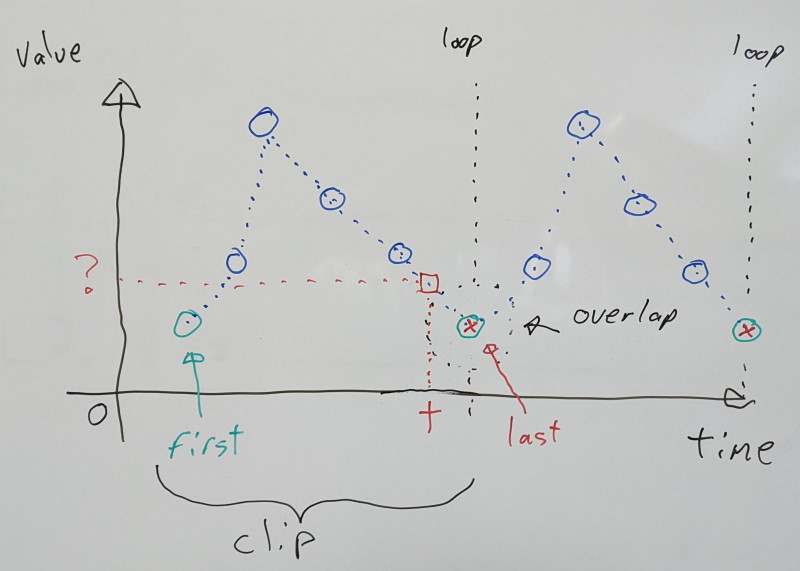
Calculating the clip duration can be achieved by taking the number of samples and subtracting one before multiplying by the sampling rate (e.g. 30 FPS). We subtract by one because we count how many intervals of time we have in between our samples.
If we wish to sample the clip at some time t, we normalize it by dividing by the clip duration to bring the resulting value between [0.0, 1.0] inclusive.
We can then multiply it with the last sample index to find which two values to use when interpolating:
- The first sample is the
floorvalue (or the truncated value) - The second sample is the
ceilvalue (or simply the first + 1) we clamp with the last sample index
The interpolation alpha value between the two is the resulting fractional part.
Reconstructing our desired value can then be achieved by interpolating the two samples.
float duration = (num_samples - 1) * sample_rate;
float normalized_t = t / duration;
float sample_offset = normalized_t * (num_samples - 1);
int first_sample = trunc(sample_offset);
int second_sample = min(first_sample + 1, num_samples - 1);
float interpolation_alpha = sample_offset - first_sample;
float result = lerp(sample_values[first_sample], sample_values[second_sample], interpolation_alpha);
This works for any sequence with at least one sample, regardless of whether or not it loops. By design, we never interpolate between the first and last samples as playback loops around.
This is the behavior in ACL v2.0 and prior. No effort had been made to take advantage of looping animations.
Wrapping loops
Wrapping strips the last sample, and instead uses the first sample to interpolate with. As a result, unlike with the clamp mode, it will interpolate between the first and last samples as playback loops around.
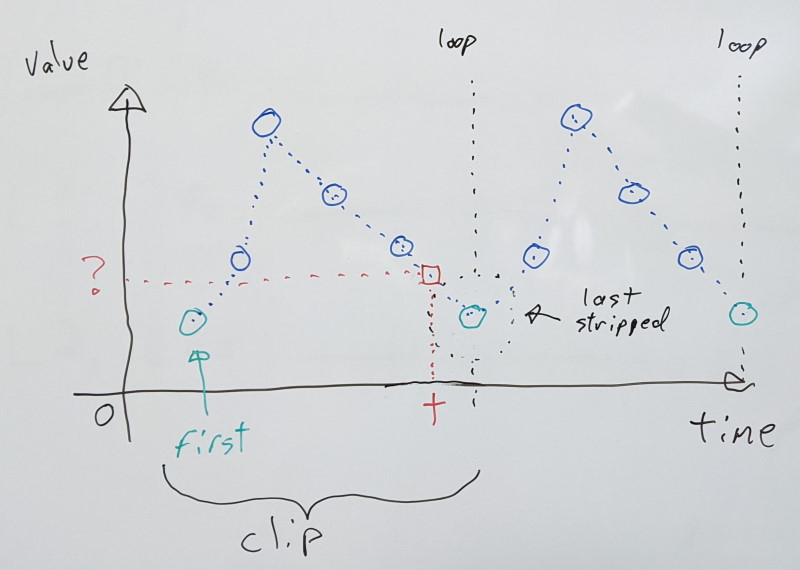
This complicates things because it means that the duration of our clip is no longer a function of the number of samples actually present. One less sample is stored, but we have to remember to account for our repeating first sample.
Accounting for that fact, this gives us the following:
float duration = num_samples * sample_rate;
float normalized_t = t / duration;
float sample_offset = normalized_t * num_samples;
int first_sample = trunc(sample_offset);
int second_sample = first_sample + 1;
if (first_sample == num_samples) {
// Sampling the last sample with full weight, use the first sample
first_sample = second_sample = 0;
sample_offset = 0.0f;
}
else if (second_sample == num_samples) {
// Interpolating with the last sample, use the first sample
second_sample = 0;
}
float interpolation_alpha = sample_offset - first_sample;
float result = lerp(sample_values[first_sample], sample_values[second_sample], interpolation_alpha);
By design, the above logic only works for clips which have had their last sample removed. As such, it is not suitable for non-looping clips.
How much memory does it save?
I analyzed the animation clips from Paragon to see how much memory a single key frame (whole pose at a point in time) uses. The results were somewhat underwhelming to say the least.
| Paragon | Before | After |
|---|---|---|
| Compressed size | 208.93 MB | 208.71 MB |
| Track error 99th percentile | 0.0099 cm | 0.0099 cm |
Roughly 200 KB were saved or about 0.1% even though 1454 clips (out of 6558) were identified as looping. Looking deeper into the data shows the following hard truth: animated key frame data is pretty small to begin with.
| Paragon | 50th percentile | 85th percentile | 99th percentile |
|---|---|---|---|
| Animated frame size | 146.62 Bytes | 328.88 Bytes | 756.38 Bytes |
Half the clips have an animated key frame size of 146 bytes or smaller. Because joints are not all animated, they do not all benefit equally.
Here is the full distribution of how much memory was saved as a percentage of the original size:
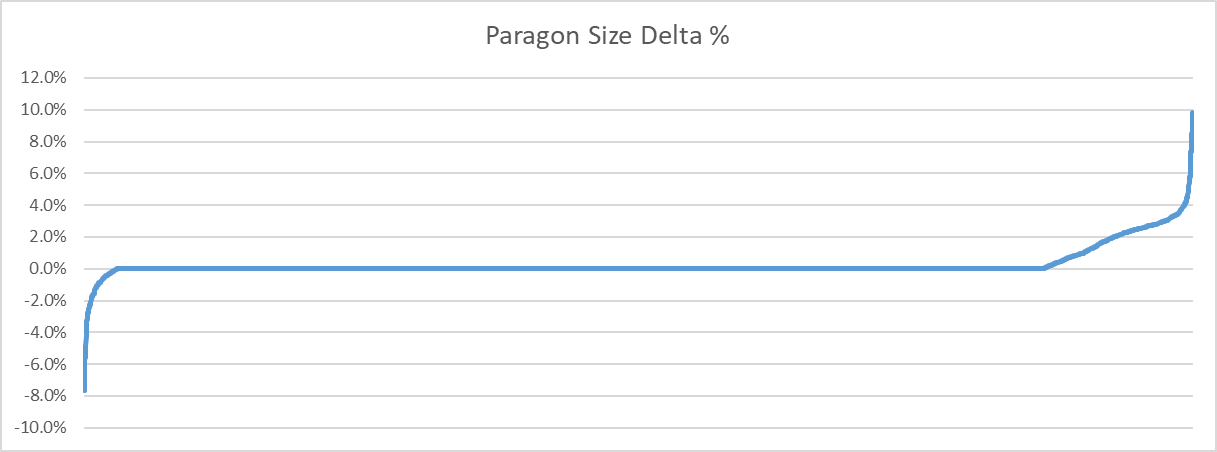
Interestingly, some clips end up larger when the last key frame is removed. How come? It all boils down to the fact that ACL tries to split the number of key frames evenly across all sub-segments it generates. Segments are used to improve accuracy and lower the memory footprint but the current method is naive and will be improved on in the future. As such, when a loop is detected, ACL can do one of two things: the last key frame can be removed before segments are created or afterwards. I opted to do so before to ensure proper balancing. As such, through the re-balancing that occurs, some clips can end up being larger. Either way, the small size of the animated key frame data puts a fairly low ceiling on how much this optimization can save.
Side node: thanks to this, I found a small bug that impacts a very small subset of clips. Clips impacted by this ended up with segments containing more key frames than they otherwise would have resulting in a slightly larger memory footprint.
Caveats
Special care must be taken when removing the last sample, as joint tracks are not all equal. In a looping clip, the last sample will match the first for joints which have a direct impact on visual feedback to the user, but it might not be the case for joints which have an indirect impact, or those that have no impact. For example, while the joint for a character’s hand has direct visual feedback as we see it on screen, other joints like the root have only indirect feedback (through root motion), and any number of custom invisible joints might exist for things like inverse kinematics and other metadata required.
A looping clip with root motion might have a perfectly matching last sample for the visible portion of the character pose, but the root value might differ between the two. When this is the case, removing the last sample means truncating important data! For that reason, ACL only detects wrapping when ALL joints repeat perfectly between their first and last sample.
Why is root motion special?
An animation clip contains a series of transforms for every joint at different points in time. To remove as much redundancy as possible, joints are stored relative to their parent (if they have one, local space). In order to display the visual mesh, each joint transform is combined with its parent, recursively, all the way to the root of the character (converting from local space to object space).
In an animation editor, a character will be animated relative to some origin point at [0,0,0] (object space). However, in practice, we need to be able to play that animation anywhere in the world (world space). As such, we need to transform joints from object space into world space by using the character’s transform.
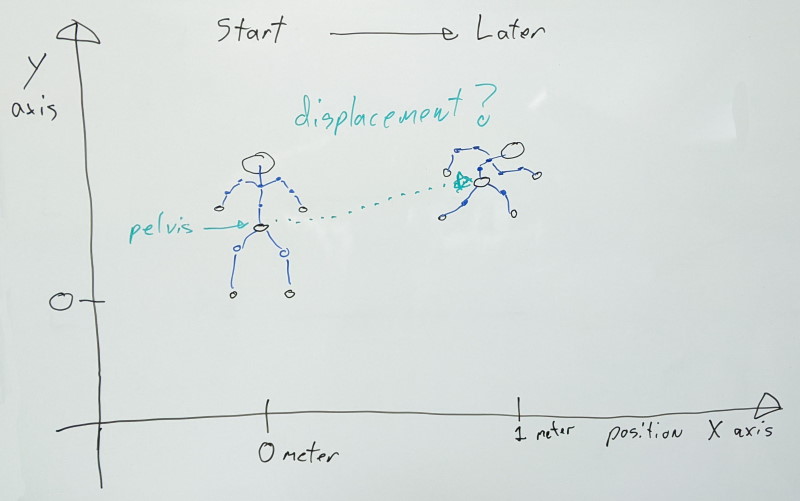
The pelvis joint is usually the highest most visible joint in the hierarchy with the legs and spine in turn parented to it, etc. When the character moves, every joint has direct visual feedback as their movement deforms the parts of the visual mesh attached to them (through the rigid skinning process).
Now what happens if we wish to make a walking animation where the character moves at some desired speed? If the pelvis joint is the highest most joint in the hierarchy, this motion will happen there, and it will drag every joint parented to it (because children transforms are stored relative to their parent to avoid having redundant motion in every joint).
This is problematic because now, the character motion is mixed in with what the pelvis does in this particular clip (e.g. swaying back and forth). It is no longer possible to extract cleanly that motion free from the noise of the animation. As the animation plays back in the world, things might be attached to the character (e.g. camera) that we wish to attach to the character himself, and not some particular joint. If only the joints move, this won’t work. As such, we often want to extract this character motion and apply it as a delta from the previous animation update. We would remove this motion from the joints, and instead transfer it onto the character.
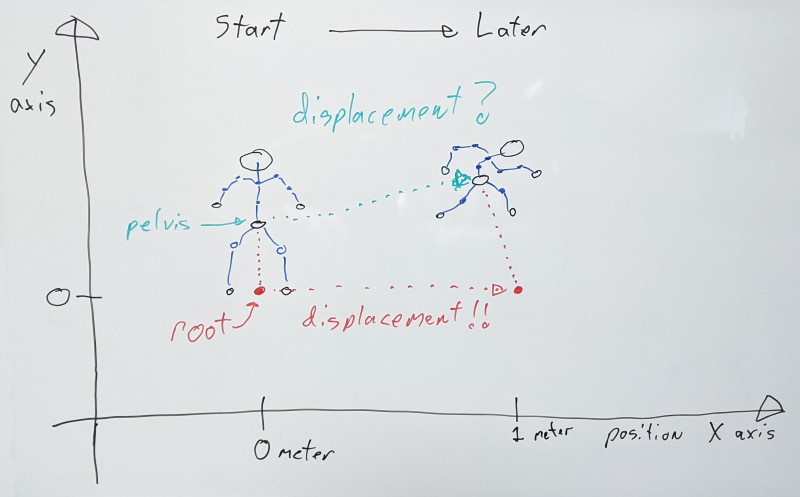
To simplify this process, character motion is generally stored in a root joint that sits highest in the joint hierarchy. This joint does not directly move anything, and we instead extract the character motion from it and apply it onto the character.
As a result, character motion is stored as an absolute displacement value relative to that [0,0,0] origin mentioned earlier. In a 1-second-long animation where the character moves 1 meter, on the first sample the root value will be zero meters and on the last sample, the value is 1 meter. Values in between can vary depending on how the character velocity changes. As such, even if the character pose is identical between the first and last samples, their root joints differ and CANNOT be interpolated between.
When we sample the animation, we can find out our character motion delta as follow: current_root_position - previous_root_position. This gives us how much the character moved since the last update. When the animation loops, we must break this calculation down into two parts:
last_root_position - previous_root_positionto get the trailing end of the motioncurrent_root_position - first_root_positionto get the rest of the motion (note thatfirst_root_positionis usually zero and can be omitted)
There is also one more special case to consider: if the animation loops more than once since the last update. This can happen for any number of reasons: playback rate changes, the character was off screen for a while and is now visible and updating again, etc. When this happens, we must extract the total displacement of the animation and multiply it by how many times we looped through. The total displacement value lives in our last sample and can simply be read from there: last_root_position * num_loops.
If, for whatever reason, we forcibly remove the last sample, we will no longer have information on how fast the root was moving as it wrapped around. This velocity information is permanently lost and cannot be reconstructed.
It is generally desirable to keep the number of samples for every joints the same for compression purposes within an animation clip. If we don’t, we would need to either store how many samples we have per joints (and there can be many) or whether the last sample has been removed or not. This added overhead and complexity is ideally one we’d like to do without.
It is thus tempting to remove the last sample and estimate the missing value somehow. While this might work with few to no visible artifacts, it can have subtle implications when other things that should be moving at the same overall rate are visible on screen. For example, two characters might be running side by side at the same velocity, but with different animations. Just because the overall velocity is the same (e.g. both move at 1 meter per second), it does not mean that the velocity on the last sample matches. One animation might start fast and slow down before looping, while the other does the opposite. If this is the case, both characters will end up slowly drifting from each other even though they should not.