Animation Compression Library: Release 0.6.0
10 Jan 2018Hot off the press, ACL v0.6 has just been released and contains lots of great things!
This release focused primarily on extending the platform support as well as improving the accuracy. Proper Linux and OS X support was added as well as the x86 architecture. As always, the list of supported platforms is in the readme. This was made possible thanks to continuous build integration which has been added and contributed in part by Michał Janiszewski!
Another notable mention is that the backlog and roadmap have been migrated to GitHub Issues. This ensures complete transparency with where the project is going.
Compiler battle royal
Now that we have all of these compilers and platforms supported, I thought it would make sense to measure everything at least once on the full data set from Carnegie-Mellon University.
Another thing I wanted to measure is how much do we gain from hyper-threading and last but not least, I thought it would be interesting to include x86 as well as x64.
Here is my setup to measure:
- Windows 10 running on an Intel i7-6850K with 6 physical cores and 12 logical cores
- Ubuntu 16.04 running in VirtualBox with 6 cores assigned
- OS X running on an Intel i5-4288U with 2 physical cores and 4 logical cores
The acl_compressor.py script is used to compress multiple clips in parallel in independent processes. Each clip runs in its own process.
Every platform used a Release build with AVX enabled. The wall clock time is the cummulative time it took to run everything: compression, decompression to measure accuracy, reading the clip, writing the stats, etc. On the other hand, the total thread time measures the total sum of time the threads each spent on compression.
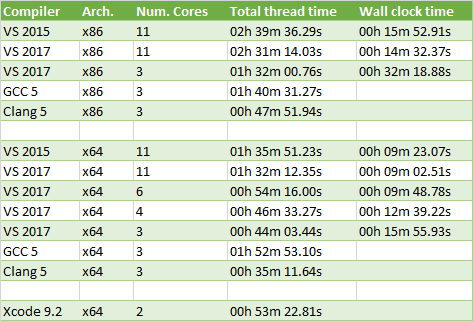
A number of things stand out:
- x86 is slower for VS 2015 (66.5% slower) , VS 2017 (64.0% slower with 11 cores, 108.8% slower with 3 cores), and Clang 5 (36.0% slower) but it seems to be faster for GCC 5 (10.9% faster)
- Hyper-threading barely helps at all: going from 6 cores to 11 with VS 2017 was only 7.8% faster but the total thread time increases by 69.9%
- Clang 5 with x64 wins hands down, it is 25.2% faster than VS 2017 and 220.8% faster than GCC 5
GCC 5 performs so bad here that I am wondering if the default CMake compiler flags for Release builds are sane or if I made a mistake somewhere. Clang 5 really blew me away: despite running in a VM it significantly outperforms all the other compilers with both x86 and x64.
As expected, hyper-threading does not help all that much. When clips are compressed, most of the data manipulated can fit within the L2 or L3 caches. With so little IO made, animation compression is primarily CPU bound. Overall this leaves very little opportunity for a neighbor thread to execute since they hardly ever stall on expensive operations.
Accuracy improvements
As I mentioned when the Paragon data set was announced, some exotic clips brought to the surface some unusual accuracy issues. These were all investigated and they generally fell into one or both of these categories:
- Very small and very large scale coupled with very large translation caused unacceptable accuracy loss when using affine matrices to calculate the error
- Very large translations in a long bone chain can lead to significant accuracy loss
In order to fix the first issue, how we handle the error metric was refactored to better allow a game engine to supply their own. This is documented here. Ultimately what is most important about the error metric is that it closely approximates how the error will look in the host game engine. Some game engines use affine matrices to convert the local space bone transform into object or world space while others use Vector-Quaternion-Vector (VQV). ACL now supports both ways to calculate the error and the default we will be using for all of our statistics is the later as it more closely matches what Unreal 4 does. This did not measurably impact the compression results but it did improve the accuracy of the more exotic clips and the overall compression time is faster.
However, the problem of large translations in long bone chains has not been addressed. I compared how the error looked in Unreal 4 and it does a much better job than ACL for the time being on those few clips. This is because they implement error compensation which is something that ACL has not implemented yet. In the meantime, ACL is perfectly safe for production use and if these rare clips with a visible error do pop up, less aggressive compression settings can be used. Only 3 clips within the Paragon data set suffer from this.
Ultimately a lot of the error introduced for both ACL and Unreal 4 comes from the rotation format we use internally: we drop the quaternion W component. This works well enough when its value is close to 1.0 as the square-root used to reconstruct it is accurate in that range but it fails spectacularly when the value is very small and close to 0.0. I already have plans to try two other rotation formats to help resolve this issue: dropping the largest quaternion component and using the quaternion logarithm instead.
Updated stats
While investigating the accuracy issues and comparing against Unreal 4 I noticed that a fix I previously made locally was partially incorrect and in rare cases could lead to bad things happening. This has been fixed and the statistics and graphs for UE 4.15 were updated for CMU and Paragon. The results are very close to what they were before.
The accuracy improvements from this release are a bit more visible on the Paragon data set.
Next steps
At this point, I can pretty confidently say that ACL is ready for production use but many things are still missing for the library to be of production quality. While the performance and accuracy are good enough, iOS support is still missing, support for additive animations is missing, as well as lots of unit testing, documentation, and clean up.
The next release will focus on:
- Cleaning up
- Adding lots of unit tests
- iOS support
- Better Android support
- Many other things