Animation Compression Library: Release 0.5.0
23 Nov 2017Today marks the release of ACL v0.5. Once again, lots of great things were included in this release but three things stand out:
- Full 3D scale support
- Android support (tested within Unreal Engine 4.15)
- A fix to the variable quantization optimization algorithm
The third point in particular needs explaining. Initially, I did not intend to make significant changes in this release to the way compression was done beyond the scale support and whatever fixes Android required. However, while investigating accuracy issues within an exotic clip, I noticed a bug. Upon fixing it (and very unexpectedly), everything kicked into overdrive.
Performance results
On the Carnegie-Mellon University (CMU) data set, the memory footprint reduced by 18.4% with little to no change to the accuracy of the overwhelming majority of clips and a slight accuracy increase to some of them! Sadly, the compression speed suffered a bit as a result and it is now about 1.5x slower than v0.4. In my opinion, this is an entirely acceptable trade-off!
Compared to UE 4.15, ACL now stands 37.8% smaller and 2.82x faster (single threaded) to compress on CMU. No small feat!
In light of these new numbers, all the charts have been updated and can be found here. Here are the most interesting:
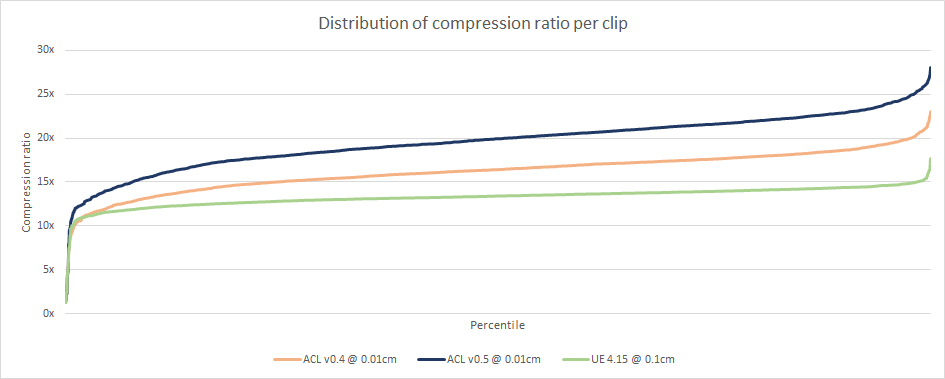
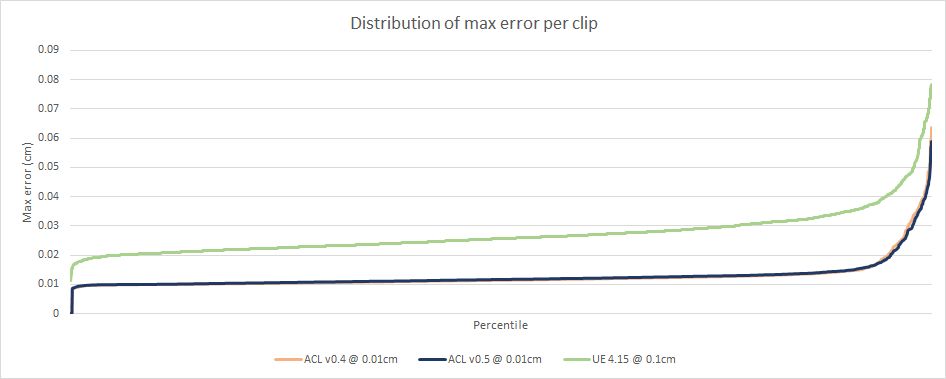
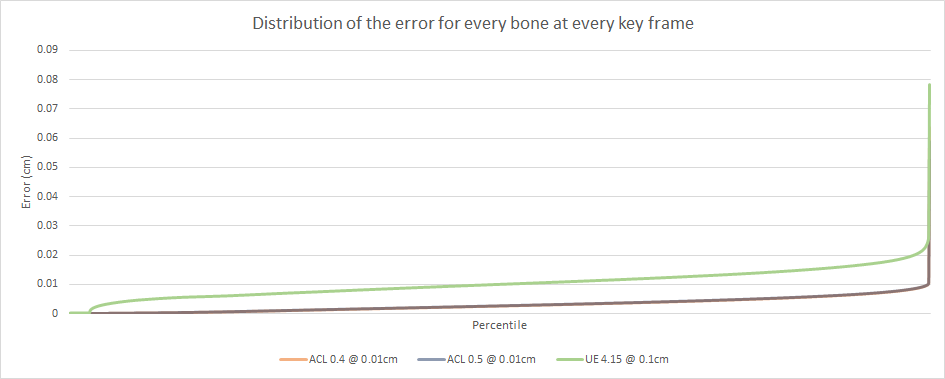
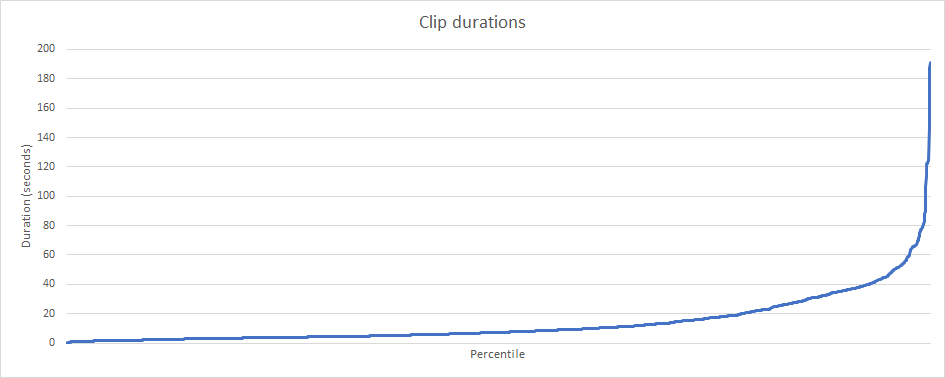
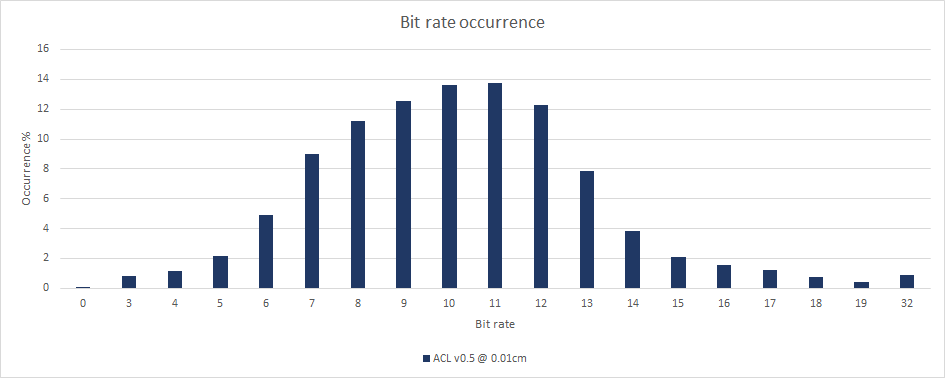
I also extracted two new charts: the distribution of clip durations within CMU and the distribution of which bit rates ended up selected by the algorithm. A bit rate of 6 means that 6 bits per component are used. Every track (rotation, translation, and scale) sample has 3 components (X, Y, Z) which means 18 bits per sample.
Next steps
The focus of the next few months will be more platform support (Linux, OS X, and iOS in that order) as well as improving the accuracy. A new data set I got my hands on showed edge cases that are not too uncommon from real video games where the accuracy is not good enough. Part of the accuracy loss comes from storing the segment range on 8 bits per component and the fact that we use 32 bit floats to perform the decompression arithmetic. As such, a new research branch will be created to investigate using 64 bit floats to perform the arithmetic and a fixed point represetation as well. A separate blog post will be written with the conclusion of this research.