ACL decompression performance
11 May 2018At long last I finally got around to measuring the decompression performance of ACL. This blog post will detail the baseline performance from which we will measure future progress. As I have previously mentioned, no effort has been made so far to optimize the decompression and I hope to remedy that following the v1.0 release scheduled around June 2018.
In order to establish a reliable data set to measure against, I use the same 42 clips used for regression testing plus 5 more from the Matinee fight scene. To keep things interesting, I measure performance on everything I have on hand:
- Desktop: Intel i7-6850K @ 3.8 GHz
- Laptop: MacBook Pro mid 2014 @ 2.6 GHz
- Phone: Android Nexus 5X @ 1.8 GHz
- Tablet: iPad Pro 10.5 inch @ 2.39 GHz
The first two use both x86 and x64 while the later two use armv7-a and arm64 respectively. Furthermore, on the desktop I also compare VS 2015, VS 2017, GCC 7, and Clang 5. The more data, the merrier!
Decompression is measured both with a warm CPU cache to remove the memory fetches as much as possible from the equation as well as with a cold CPU cache to simulate a more realistic game engine playback scenario.
Three forms of playback are measured: forward, backward, and random.
Each clip is sampled 3 times at every key frame based on the clip sample rate and the smallest value is retained for that key.
Finally, two ways to decompress are profiled: decompressing a whole pose in one go (decompress_pose), and decompressing a whole pose bone by bone (decompress_bone).
The profiling harness is not perfect but I hope the extensive data pulled from it will be sufficient for our purposes.
Playback direction
In a real game, the overwhelming majority of clips play forward in time. Some clips play backwards (e.g. opening and closing a chest might use the same animation played in reverse) and a few others play randomly (e.g. driven by a thumb stick).
Not all algorithms will exhibit the same performance regardless of playback direction. In particular, forms of delta encoding as well as any caching of the last played position will severely degrade when the playback isn’t the one optimized for (as is often the case with key reduction techniques due to the data being sorted by time).
ACL currently uses the uniformly sampled algorithm which offers consistent performance regardless of the playback direction. To validate this claim, I hand picked 3 clips that are fairly long: 104_30 (44 bones, 11 seconds) from CMU, and Trooper_1 (71 bones, 66 seconds) and Trooper_Main (541 bones, 66 seconds) from the Matinee fight scene. To visualize the performance, I used a box and whiskers chart which shows concisely the min/max as well as the quartiles. Forward playback is shown in Red, backward in Green, and random in Blue.
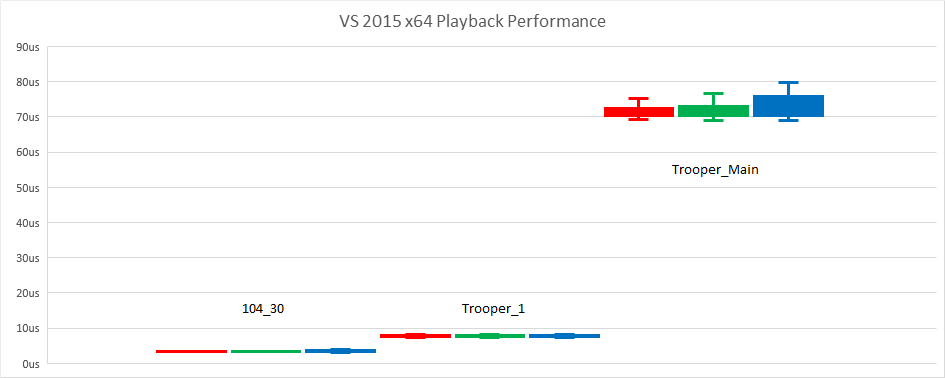
As we can see, the performance is identical for all intents and purposes regardless of the playback direction on my desktop with VS 2015 x64. Let’s see if this claim holds true on my iPad as well.
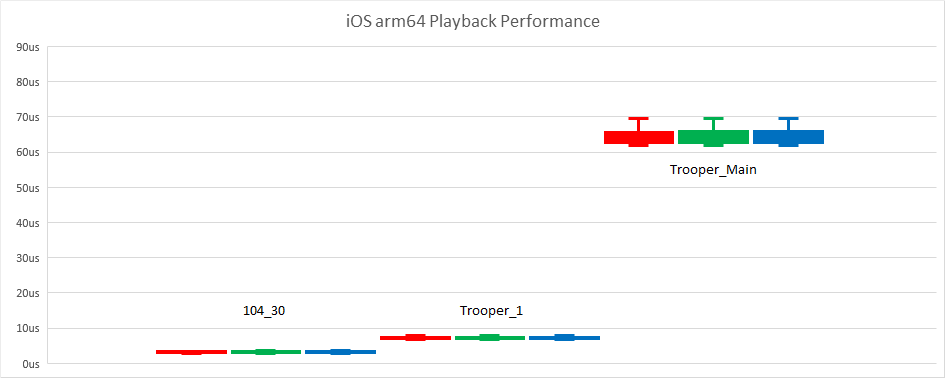
Here again we see that the performance is consistent. One thing that shows up on this chart is that, surprisingly, the iPad performance is often better than my desktop! That is INSANE and I nearly fell off my chair when I first saw this. Not only is the CPU clocked at a lower frequency but the desktop code makes use of SSE and AVX where it can for all basic vector arithmetic while there is currently no corresponding NEON SIMD support. I double and triple checked the numbers and the code. Suspecting that the compiler might be playing a big part in this, I undertook to dump all the compiler stats on desktop; something I did not originally intend to do. Read on!
The CPU cache
Because animation clips are typically sampled once per rendered image, the CPU cache will generally always be cold during decompression. Fortunately for us, modern CPUs offer hardware prefetching which greatly helps when reads are linear. The uniformly sampled algorithm ACL uses is uniquely optimized for this with ALL reads being linear and split into 4 streams: constant track values, clip range data, segment range data, and the animated segment data.
Notes: ACL does not currently have any software prefetching and the constant track and clip range data will later be merged into a single stream since a track is one of three types: default (in which case there is neither constant nor range data), constant with no range data, or animated with range data and thus not constant.
For this reason, a cold cache is what will most interest us. That being said, I also measured with a warm CPU cache. This will allow us to see how much time is spent waiting on memory versus executing instructions. It will also allow us to compare the various platforms in terms of CPU and memory speed.
In the following graphs, the x86 performance was omitted because for every compiler it is slower than x64 (ranging from 25% slower up to 200%) except for my OS X laptop where the performance was nearly identical. I also omitted the VS 2017 performance because it was identical to VS 2015. Forward playback is used along with decompress_pose. The median decompression time is shown.
Two new clips were added to the graphs to get a better picture.
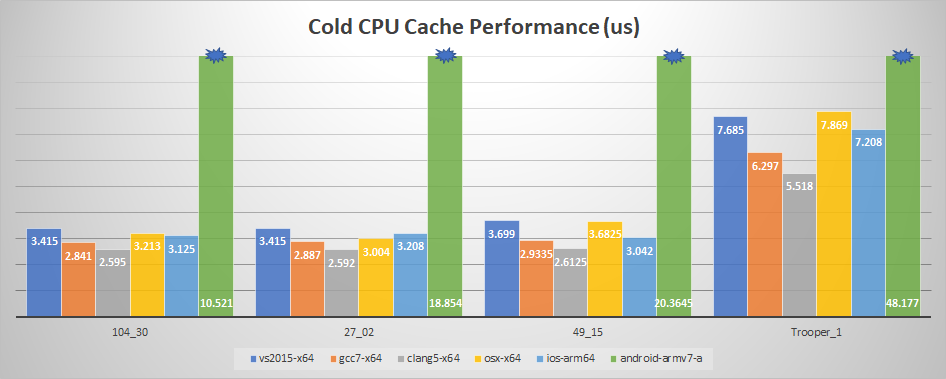
Again, we can see that the iPad outperforms almost everything with a cold cache except on the desktop with GCC 7 and Clang 5. It is clear that Clang does an outstanding job and plays an integral part in the surprising iPad performance. Another point worth noting is that its memory is faster than what I have in my desktop. My iPad has memory clocked at 1600 MHz (25 GB/s) while my desktop has its memory clocked at 1067 MHz (16.6 GB/s).
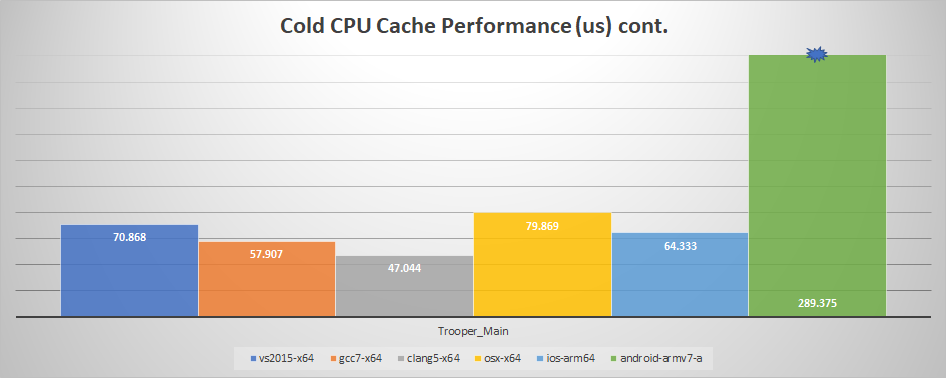
And now with a warm cache:
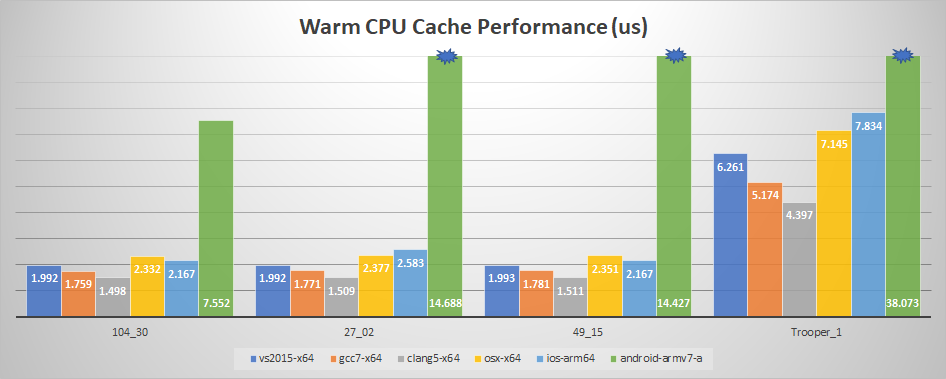
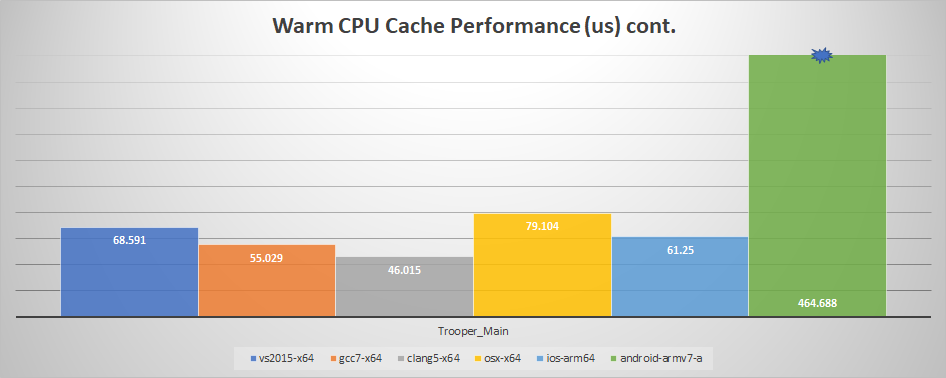
We can see that the iPad now loses out to VS 2015 with one exception: Trooper_Main. Why is that? That particular clip should easily fit within the CPU cache: only about 40KB is touched when sampling (or about 650 cache lines). Further research led to another interesting fact: the iPad A10X processor has a 64KB L1 data cache per core (and 8 MB L2 shared) while my i7-6850K has a 32KB L1 data cache and a 256KB L2 (with 15MB L3 shared). The clip thus fits entirely within the L1 on the iPad but needs to be fetched from the L2 on desktop.
Another takeaway from these graphs is that GCC 7 beats VS 2015 and Clang 5 beats both hands down on my desktop.
Finally, my Nexus 5X is really slow. On all the graphs, it exceeded any reasonable scale and I had to truncate it. I included it for the sake of completeness and to get a sense of how much slower it was.
Decompression method
ACL currently offers two ways to decompress: decompress_pose and decompress_bone. The former is more efficient if the whole pose is required but in practice it is very common to decompress specific bones individually or to decompress a pose bone by bone.
The following charts use the median decompression time with a cold CPU cache and forward playback.
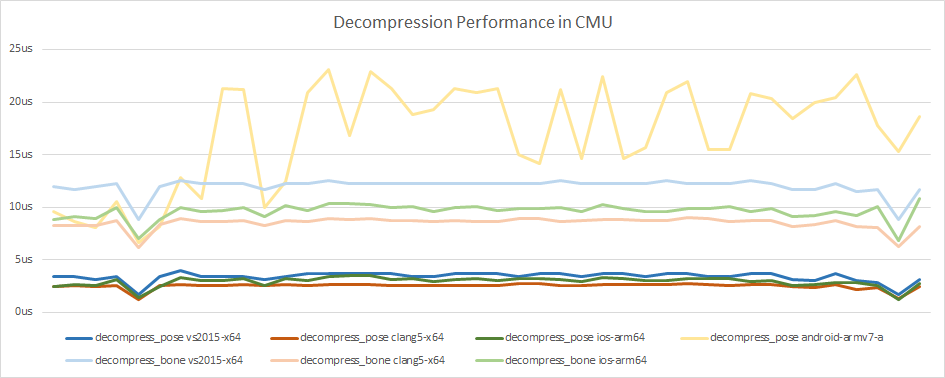
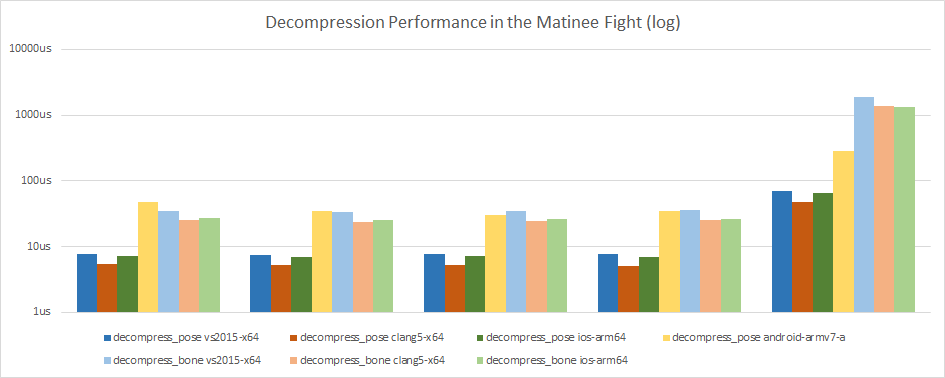
Once more, we see very clearly how outstanding and consistent the iPad performance is. The numbers for the Nexus 5X are very noisy in comparison in large part because of the slower memory and larger footprint of some clips (decompress_bone is not shown for Android because it was far too slow and prevented a clean view of everything else).
We can clearly see that decompressing each bone separately is much slower and this is entirely because at the time of writing, each bone not required needs to be skipped over instead of using a direct look up with an offset. This will be optimized soon and the performance should end up much closer.
Conclusion
Despite having no external reference frame to compare them against, I could confirm and validate my hunches as well as observe a few interesting things:
- My Nexus 5X is really slow …
- Both GCC 7 and Clang 5 generate much better code than VS 2017
decompress_boneis much slower than it needs to be- The playback direction has no impact on performance
By far the most surprising thing to me was the iPad performance. Even though what I measure is not representative of ordinary application code, the numbers clearly demonstrate that the single core decompression performance matches that of a modern desktop. It might even exceed the single core performance of an Xbox One or PlayStation 4! Wow!!
I do have some baseline Unreal 4 numbers on hand but this blog post is already getting long and the next ACL version aims to be integrated into a native Unreal 4 plugin which will allow for a superior comparison to be made. However, they do show that ACL will be very close and will likely exceed the UE 4.15 decompression performance; stay tuned!